
Tiempo de Lectura: 5 minutos
Como vimos en el artículo del ecosistema Hadoop podemos encontrar distintos proyectos para realizar consultas, trabajar con bases de datos y hasta realizar estudios de machine learning entre otros. Por eso en éste artículo hablaremos de Pig, un proyecto de código abierto de Apache, que ofrece un lenguaje de alto nivel para el análisis de flujo de datos dentro de un entorno de ejecución en paralelo como Hadoop.
¿Qué es Pig Hadoop?
Pig es una plataforma de scripting desarrollado originalmente por Yahoo! en el 2006 y fue adoptado un año después por Apache Software Foundation para convertirse en un subproyecto de Apache.
Pig provee un lenguaje de alto nivel para crear flujos de datos llamado Pig Latin el cual permite realizar programas MapReduce de forma simple y en pocas líneas de código. La gran ventaja es que no es necesario saber programar en Java, pues Pig posee dentro de su infraestructura un compilador capaz de producir secuencias MapRecude, lo que permite a los usuarios Hadoop enfocarse más en el análisis de los datos que el desarrollo mismo de los programas.
La gran ventaja que tiene Pig con Pig Latin los scripts pueden ser ampliados utilizando funciones definidas por el usuario (UDF) en distintos lenguajes tales como Java, Ruby, Python, JavaScript y Groovy.
Su nombre nos dice mucho de lo que es capaz, Pig puede trabajar con datos de cualquier origen, incluyendo estructurados y no estructurados, y almacena los resultados dentro del Data File System de Hadoop. Los scripts de Pig son trasladados en series de Jobs MapReduce los cuales se ejecutan dentro del cluster Hadoop.
Como se mencionó Pig corre sobre Hadoop haciendo uso del sistema HDFS y del sistema de procesamiento MapReduce. La ventaja de Pig es que es un entorno de alto nivel, donde los usuarios disponen de estructuras y funciones predefinidas que son posibles de usar directamente o combinar para escribir código muy complejo en forma muy sencilla.
¿Qué es Pig Latin?
Pig Latin es un lenguaje de flujos de datos que trabaja en paralelo. Lo que quiere decir que permite a los programadores describir cómo los datos provenientes de una o más entradas deben ser leídos, procesados y luego almacenados a uno o más flujos de salida en paralelo.
La sintaxis de Pig Latin es muy similar a la de SQL, aunque Pig Latin es un lenguaje de transformación de datos y, por lo tanto, es similar a los optimizadores de consultas de base de datos de los sistemas de bases de datos actuales.
Escribir programas MapReduce en Java puede consistir en más de cien líneas de código, según la complejidad de los mismos, mientas que los scripts de Pig Latin comúnmente no toman más de 10 líneas de código.
Pig Latin incluye operadores para muchas operaciones tradicionales tales como Join, Sort, Filter , etc. Como así también la capacidad de permitir a los usuarios definir sus propias funciones para leer, procesar y escribir datos.
Veamos algunos operadores:
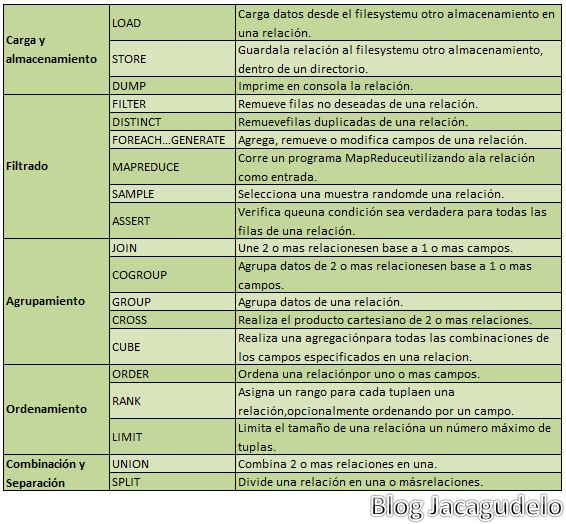
¿Cómo funciona Pig Latin?
Uno de los principales objetivos de Pig es que Pig Latin sea el lenguaje natural para los entornos de procesamientos de datos paralelos como Hadoop, ya que Pig en si ofrece varias ventajas sobre el uso de MapReduce directamente.
La programación en Pig tiene al menos 3 pasos:
- El primer paso en un programa Pig es cargar los datos que desea manipular desde HDFS.
- A continuación, ejecuta los datos a través de un conjunto de transformaciones (que, bajo las cubiertas, se traducen en un conjunto de tareas de asignación y reductor en MapReduce).
- Finalmente, DUMP para ver los datos de resultado en pantalla o STORE para almacenar los resultados en un archivo en alguna parte.
Veamos un ejemplo del script en Pig
Se requiere encontrar las páginas más visitadas del blog por usuarios con edades entre los 17 y los 23 años.
# Users = load ‘users’ as (name,age);
# Filter = filter Users by age >=17 and age <= 23;
# Pages = load ‘pages’ as (user,url);
# Jnd = join Filter by name, Pages by user;
# Grpd = group Jnd by url;
# Smmd = foreach Grpd generate group, COUNT(Jnd) as clicks;
# Srtd = order Smmd by clicks desc;
# Top5 = Limit srtd 5;
# store Top5 into ‘top5sites’;
En la primera línea del script cargamos el archivo de los usuarios declarando los datos con 2 variables (nombre y edad). Asignamos la información del usuario al input.
En la segunda línea aplicamos un filtro a los usuarios cargados que tenga la edad entre 17 y 23 años, inclusive. Todos los demás registros serán descartados así quedan solo los rangos de edad de interés. El resultado de ésta operación se almacena en la variable Filter.
Realizamos nuevamente un Load para cargar la información de las páginas visitadas con los respectivos nombres, declarando su esquema con las variables usuario y url.
En la siguiente línea realizamos una unión con Join entre Filter y Pages usando Filter.name y Pages.user como clave. Después de esta unión obtendremos todas las Urls visitadas por cada usuario.
La línea del Grpd recoge todos los registros por Url definiendo un solo registro por cada Url.
Luego con Smmd cuenta cuantos registros están recolectados junto juntos por cada Url. De forma tal que luego de esta línea sabremos, por cada Url, cuántas veces fue visitada por usuarios entre 17 y 23 años.
Ordenamos desde las más visitadas a la menos visitada con Srtd order, considerando el valor contado de la línea anterior y ordenamos por desc.
Limitamos los valores ordenados a sólo 5 resultados.
Finalmente almacenamos el resultado en HDFS en el archivo top5sites.
En Pig Latin podemos resolver problemas en 9 líneas de código y al menos 15 minutos. El mismo código en MapReduce podría llevar unas 170 líneas de código y tomar cerca de 4 horas para completar las tareas.
Ventajas de Pig Latin
- El uso de operadores como Join, Filter, Group by, Order, ect, los cuales en MapReduce resultan muy costosos.
- Puede operar con cualquier tipo de datos (estructurado, semi-estructurado o no estructurado).
- Diseñado para ser fácilmente controlado y modificado por los usuarios, permitiendo agregar funciones definidas de diferentes lenguajes.
- Permite ejecutar tareas MapReduce fácilmente.
- Procesa datos rápidamente. La intención es mejorar el rendimiento y no las funcionalidades, lo que evita ue demasiada funcionalidad le impida “volar”.
- Permite ejecución customizable por el usuario.
¿Cómo podríamos usar Pig?
Pig generalmente es usado para realizar tareas que involucran procesamiento de grandes bancos de datos pensando resultados en poco tiempo.
Un uso muy común es procesar grandes fuentes de datos como los registros web, podríamos capturar las interacciones de los usuarios en un sitio web y dividir alos usuarios en varios segmentos, así, podríamos realizar modelos predictivos para cada segmento de manera que podamos predecir a que tipos de anuncios o noticias responden mejor cada uno y poder mostrar solo los anuncios que sean más propensos a hacer clic o publicar noticias con as posibilidades de atraer a los usuarios.
También es usado comúnmente para procesos ETL debido a que permite analizar flujos de datos con operadores muy sencillos como agrupación, unión y agregación. Ya que los datos pueden ser presentados en diversos formatos, necesitan ser procesados y almacenados en una base de datos para posteriormente ejecutar queries sobre ellos. Pig además permite paralelización gracias a Hadoop y aunque diversas herramientas ETL permiten descomponer los procesos en pequeños segmentos, los scripts de Pig son aún más simples y fáciles de entender.
Sin embargo, esto no indica que Pig sea un reemplazo de una herramienta de ETL, puesto que además de que no provee funcionalidades específicas de un ETL (y que no fue desarrollado para tal fin), el uso de Pig para todos los procesos de ETL sería una exageración cuando los datos razonablemente pueden manejarse en una instancia de base de datos.
Conclusión sobre Pig
Como vimos Pig es una herramienta increíblemente potente, no solo por permitir el procesamiento de cualquier tipo de datos si no porque además permite paralelizar los procesos lo que nos da una ventaja al poder procesar muchos más datos que en una herramienta ETL tradicional. Sus scripts son mucho más cortos, sencillos y potentes que MapReduce permitiendo el uso de funciones personales lo que da una mayor funcionalidad y versatilidad, sin duda una herramienta a tener presente a la hora de analizar o proponer una solución Big Data…eso sí, debes contemplar el tiempo de capacitación y adaptación a la misma.
¿Qué te pareció Pig? ¿Consideras que debe ser tenido en cuenta en una solución Big Data con Hadoop? ¿Crees que puede reemplazar una herramienta ETL?



