Una de las principales fuentes del Big Data son la bases de datos relaciones, en una organización pueden existir millones de registros en distintas tablas, transacciones por segundo o incluso muchos años de historia. Lo más probable es que no se exploten dichos datos y no se beneficien del gran potencial que tienen en su poder, pues procesar tal cantidad de datos con sistemas tradicionales es un gran reto.
Este es uno de los principales usos del Big Data, donde las organizaciones pueden contar con mucha historia almacenada esperando ser analizada en Hadoop (Map Reduce, Machine Learning, Predictive, etc). Es por eso que Hadoop cuenta con una herramienta llamada Sqoop la cual te permite transferir datos desde distintos RDBMS a Hadoop y de Haddop a RDBMS.
¿Qué es Sqoop?
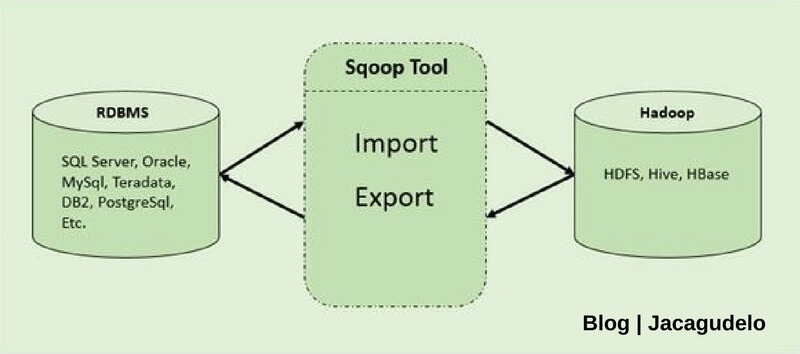
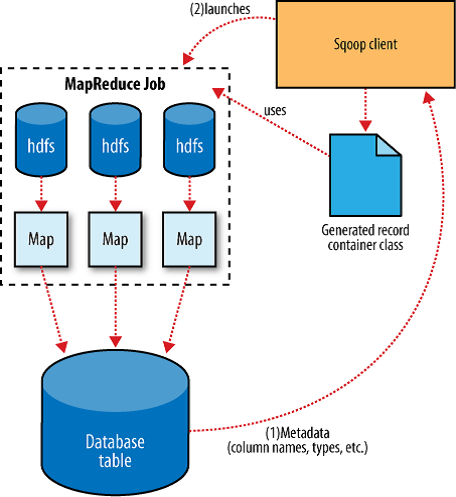
Sqoop es una herramienta cuya principal funcionalidad es transferir datos entre bases de datos relacionales o Data Warehouse y Hadoop. Sqoop automatiza la mayor parte de los procesos de transferencia, basándose en la base de datos para describir el esquema de los datos a importar, además para su funcionamiento utiliza MapReduce para importar y exportar los datos, lo que proporciona una operación en paralelo, así como tolerancia a fallos.
Sqoop le permite a los usuarios especificar la ubicación de destino dentro de Hadoop (pueden tablas Hive o HBASE) e instruir a Sqoop para mover datos de Oracle, Sql Server, Teradata u otras bases de datos relacionales al destino.
¿Cómo Trabaja Sqoop?
Sqoop funciona como una capa intermedia entre las bases de datos relacionales y Hadoop:
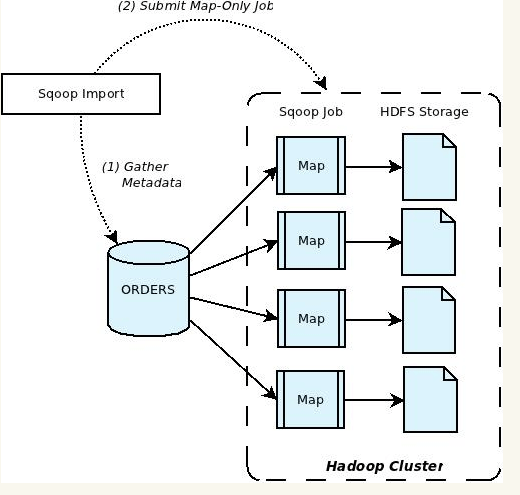
Import Sqoop
Sqoop escribe desde las tablas o consultas Sql específicas registro por registro paralelamente, por lo cual el resultado pueden ser múltiples archivos almacenados en HDFS con una copia de los datos importados. Estos archivos podrían ser txt separados por comas o tabulaciones, binarios Avro o SequenceFiles
Al ver la siguiente lista de argumentos para realizar la importación, podemos ver que el proceso inicial no es del otro mundo y utiliza casi la misma estructura que si estuviéramos realizando una conexión a una base de datos específica desde cualquier lenguaje de programación, adicionándole por supuesto los datos de Hadoop:
Generalmente Sqoop selecciona todos los campos de la tabla o vista origen a importar manteniendo el orden natural de los mismos.
$ sqoop import –query ‘SELECT a.*, b.* FROM a JOIN b on (a.id == b.id) WHERE $CONDITIONS’ –split-by a.id /
–target-dir /user/foo/joinresults
Donde guarda los datos importados?
Por defecto Sqoop almacena los archivos de la importación en el directorio /foo dentro del directorio principal del sistema HDFS. Por ejemplo si el usuario utilizado es jacagudelo, Sqoop dejará los archivos de los resultados en la ruta /usr/jacagudelo/foo/(files).
Para ajustar este valor podemos hacer lo siguientes:
La herramienta de exportación exporta un conjunto de archivos de HDFS a un RDBMS. Los archivos dados como entrada a Sqoop contienen registros, que se llaman como filas en la tabla. Éstos se leen y analizan en un conjunto de registros y se delimitan con el delimitador especificado por el usuario.
Los principales parametros utilizar son – – export-dir el cual especifica el directorio en HDFS que contiene los datos de los archivos y – – table o – – call que identifican respectivamente la tabla destina o procedimiento almacenado a ejecutar.
Algo a tener en cuenta al momento de exportar es que Sqoop toma por defecto todas las columnas, pero podremos especificar columnas puntuales con el comando – – columns delimitándolas por comas. La advertencia aquí es que las colummnas que no se eincluyan en el proceso serán enviadas con valor NULL por defecto por lo que si la tabla destino no tiene configurado dicho permiso terminará generando error el proceso Sqoop.
Sqoop por defecto realiza un append en la tabla de destino, en esencia realiza un insert sobre cada registro. Al igual que con los campos en el caso anterior, las tablas destino podrían tener Primary Key con los cual podrían generar error de duplicidad. Este modo está destinado principalmente a exportar registros a una nueva tabla vacía destinada a recibir estos resultados.
En caso de que el destino sea una tabla existente, debemos adicionar el parámetro – – update – key donde Sqoop realizará la modificación del conjunto de datos existente en la base de datos destino. Cada registro de entrada se tratará como una instrucción UPDATE que modifica una fila existente. La modificación de la fila se determina por el nombre de columna especificado como llave –update-key.
Si ejecutamos el comando:
$ sqoop export –table bar –update-key id –connect jdbc:mysql://db.example.com/foo –export-dir /results/bar_data
Internamente el Job de Sqoop realizará lo siguiente:
UPDATE foo SET msg=’this is a test’, bar=42 WHERE id=0;
UPDATE foo SET msg=’some more data’, bar=100 WHERE id=1;
Tipos de Destino en Hadoop
Una de las principales virtudes de Hadoop es que nos brinda una gran variedad de proyectos disponibles para usar de acuerdo a nuestras necesidades, para este caso puntual contamos con 3 proyectos específicos:
Hive: Como vimos en el artículo Hive nos proporciona un ambiente de Data Warehouse sobre Hadoop con su propio lenguae de consulta muy similar al SQL, lo cual nos vendría conveniente al querer explorar nuestros datos.
HBase: HBase es una base de datos no relacional que nos permite realizar búsquedas rápidas de baja latencia en Hadoop. Agregar capacidades transaccionales a Hadoop, permitiendo a los usuarios realizar actualizaciones, inserciones y eliminaciones.
Accumulo: Aunque muy poco conocida pero no menos importante, tenemos esta base de datos NoSql de tipo Key-Column la cual podemos utilizar a nuestras necesidades.
Conclusión sobre Sqoop
Como acabamos de ver, Sqoop es una poderosa herramienta para poblar desde nuestras bases de datos relacionales y evolucionar nuestros proyectos analíticos, con sus comandos podemos trasladar nuestros datos, analizarlos mediante cualquier otra herramienta como Pig o Hive sobre Hadoop y volver a retornar el resultado a nuestras bases. Una funcionalidad muy práctica y eficaz para nuestros proyectos.
¿Qué te pareció Sqoop? ¿Consideras que debe ser tenido en cuenta en una solución Big Data con Hadoop?
Tiempo de Lectura: 5minutos
Como vimos en el artículo del ecosistema Hadoop podemos encontrar distintos proyectos para realizar consultas, trabajar con bases de datos y hasta realizar estudios de machine learning entre otros. Por eso en éste artículo hablaremos de Pig, un proyecto de código abierto de Apache, que ofrece un lenguaje de alto nivel para el análisis de flujo de datos dentro de un entorno de ejecución en paralelo como Hadoop.
¿Qué es Pig Hadoop?
Pig es una plataforma de scripting desarrollado originalmente por Yahoo! en el 2006 y fue adoptado un año después por Apache Software Foundation para convertirse en un subproyecto de Apache.
Pig provee un lenguaje de alto nivel para crear flujos de datos llamado Pig Latin el cual permite realizar programas MapReduce de forma simple y en pocas líneas de código. La gran ventaja es que no es necesario saber programar en Java, pues Pig posee dentro de su infraestructura un compilador capaz de producir secuencias MapRecude, lo que permite a los usuarios Hadoop enfocarse más en el análisis de los datos que el desarrollo mismo de los programas.
La gran ventaja que tiene Pig con Pig Latin los scripts pueden ser ampliados utilizando funciones definidas por el usuario (UDF) en distintos lenguajes tales como Java, Ruby, Python, JavaScript y Groovy.
Su nombre nos dice mucho de lo que es capaz, Pig puede trabajar con datos de cualquier origen, incluyendo estructurados y no estructurados, y almacena los resultados dentro del Data File System de Hadoop. Los scripts de Pig son trasladados en series de Jobs MapReduce los cuales se ejecutan dentro del cluster Hadoop.
Como se mencionó Pig corre sobre Hadoop haciendo uso del sistema HDFS y del sistema de procesamiento MapReduce. La ventaja de Pig es que es un entorno de alto nivel, donde los usuarios disponen de estructuras y funciones predefinidas que son posibles de usar directamente o combinar para escribir código muy complejo en forma muy sencilla.
¿Qué es Pig Latin?
Pig Latin es un lenguaje de flujos de datos que trabaja en paralelo. Lo que quiere decir que permite a los programadores describir cómo los datos provenientes de una o más entradas deben ser leídos, procesados y luego almacenados a uno o más flujos de salida en paralelo.
La sintaxis de Pig Latin es muy similar a la de SQL, aunque Pig Latin es un lenguaje de transformación de datos y, por lo tanto, es similar a los optimizadores de consultas de base de datos de los sistemas de bases de datos actuales.
Escribir programas MapReduce en Java puede consistir en más de cien líneas de código, según la complejidad de los mismos, mientas que los scripts de Pig Latin comúnmente no toman más de 10 líneas de código.
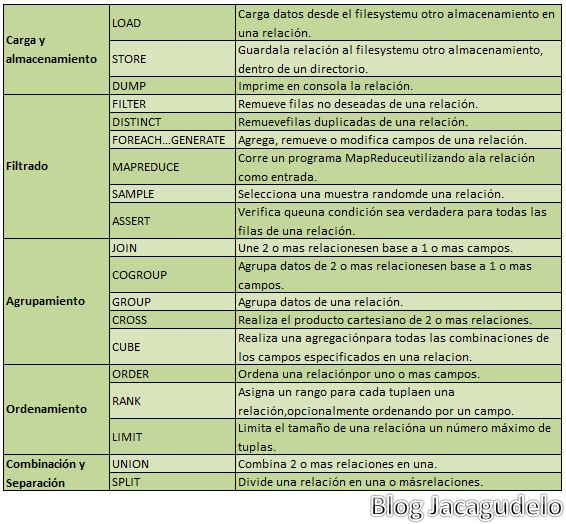
Pig Latin incluye operadores para muchas operaciones tradicionales tales como Join, Sort, Filter , etc. Como así también la capacidad de permitir a los usuarios definir sus propias funciones para leer, procesar y escribir datos.
Veamos algunos operadores:
¿Cómo funciona Pig Latin?
Uno de los principales objetivos de Pig es que Pig Latin sea el lenguaje natural para los entornos de procesamientos de datos paralelos como Hadoop, ya que Pig en si ofrece varias ventajas sobre el uso de MapReduce directamente.
La programación en Pig tiene al menos 3 pasos:
El primer paso en un programa Pig es cargar los datos que desea manipular desde HDFS.
A continuación, ejecuta los datos a través de un conjunto de transformaciones (que, bajo las cubiertas, se traducen en un conjunto de tareas de asignación y reductor en MapReduce).
Finalmente, DUMP para ver los datos de resultado en pantalla o STORE para almacenar los resultados en un archivo en alguna parte.
Veamos un ejemplo del script en Pig
Se requiere encontrar las páginas más visitadas del blog por usuarios con edades entre los 17 y los 23 años.
# Users = load ‘users’ as (name,age);
# Filter = filter Users by age >=17 and age <= 23;
# Pages = load ‘pages’ as (user,url);
# Jnd = join Filter by name, Pages by user;
# Grpd = group Jnd by url;
# Smmd = foreach Grpd generate group, COUNT(Jnd) as clicks;
# Srtd = order Smmd by clicks desc;
# Top5 = Limit srtd 5;
# store Top5 into ‘top5sites’;
En la primera línea del script cargamos el archivo de los usuarios declarando los datos con 2 variables (nombre y edad). Asignamos la información del usuario al input.
En la segunda línea aplicamos un filtro a los usuarios cargados que tenga la edad entre 17 y 23 años, inclusive. Todos los demás registros serán descartados así quedan solo los rangos de edad de interés. El resultado de ésta operación se almacena en la variable Filter.
Realizamos nuevamente un Load para cargar la información de las páginas visitadas con los respectivos nombres, declarando su esquema con las variables usuario y url.
En la siguiente línea realizamos una unión con Join entre Filter y Pages usando Filter.name y Pages.user como clave. Después de esta unión obtendremos todas las Urls visitadas por cada usuario.
La línea del Grpd recoge todos los registros por Url definiendo un solo registro por cada Url.
Luego con Smmd cuenta cuantos registros están recolectados junto juntos por cada Url. De forma tal que luego de esta línea sabremos, por cada Url, cuántas veces fue visitada por usuarios entre 17 y 23 años.
Ordenamos desde las más visitadas a la menos visitada con Srtd order, considerando el valor contado de la línea anterior y ordenamos por desc.
Limitamos los valores ordenados a sólo 5 resultados.
Finalmente almacenamos el resultado en HDFS en el archivo top5sites.
En Pig Latin podemos resolver problemas en 9 líneas de código y al menos 15 minutos. El mismo código en MapReduce podría llevar unas 170 líneas de código y tomar cerca de 4 horas para completar las tareas.
Ventajas de Pig Latin
El uso de operadores como Join, Filter, Group by, Order, ect, los cuales en MapReduce resultan muy costosos.
Puede operar con cualquier tipo de datos (estructurado, semi-estructurado o no estructurado).
Diseñado para ser fácilmente controlado y modificado por los usuarios, permitiendo agregar funciones definidas de diferentes lenguajes.
Permite ejecutar tareas MapReduce fácilmente.
Procesa datos rápidamente. La intención es mejorar el rendimiento y no las funcionalidades, lo que evita ue demasiada funcionalidad le impida “volar”.
Permite ejecución customizable por el usuario.
¿Cómo podríamos usar Pig?
Pig generalmente es usado para realizar tareas que involucran procesamiento de grandes bancos de datos pensando resultados en poco tiempo.
Un uso muy común es procesar grandes fuentes de datos como los registros web, podríamos capturar las interacciones de los usuarios en un sitio web y dividir alos usuarios en varios segmentos, así, podríamos realizar modelos predictivos para cada segmento de manera que podamos predecir a que tipos de anuncios o noticias responden mejor cada uno y poder mostrar solo los anuncios que sean más propensos a hacer clic o publicar noticias con as posibilidades de atraer a los usuarios.
También es usado comúnmente para procesos ETL debido a que permite analizar flujos de datos con operadores muy sencillos como agrupación, unión y agregación. Ya que los datos pueden ser presentados en diversos formatos, necesitan ser procesados y almacenados en una base de datos para posteriormente ejecutar queries sobre ellos. Pig además permite paralelización gracias a Hadoop y aunque diversas herramientas ETL permiten descomponer los procesos en pequeños segmentos, los scripts de Pig son aún más simples y fáciles de entender.
Sin embargo, esto no indica que Pig sea un reemplazo de una herramienta de ETL, puesto que además de que no provee funcionalidades específicas de un ETL (y que no fue desarrollado para tal fin), el uso de Pig para todos los procesos de ETL sería una exageración cuando los datos razonablemente pueden manejarse en una instancia de base de datos.
Conclusión sobre Pig
Como vimos Pig es una herramienta increíblemente potente, no solo por permitir el procesamiento de cualquier tipo de datos si no porque además permite paralelizar los procesos lo que nos da una ventaja al poder procesar muchos más datos que en una herramienta ETL tradicional. Sus scripts son mucho más cortos, sencillos y potentes que MapReduce permitiendo el uso de funciones personales lo que da una mayor funcionalidad y versatilidad, sin duda una herramienta a tener presente a la hora de analizar o proponer una solución Big Data…eso sí, debes contemplar el tiempo de capacitación y adaptación a la misma.
¿Qué te pareció Pig? ¿Consideras que debe ser tenido en cuenta en una solución Big Data con Hadoop? ¿Crees que puede reemplazar una herramienta ETL?
Aunque hoy en día la implementación de proyectos Big Data solo la llevan cabo las grandes organizaciones, creo que las demás organizaciones también se podrían beneficiar. Actualmente es mucho más fácil disponer de ambientes en Cloud, de encontrar soluciones Open Source o incluso hardware de bajo costo que les permita potencializarse, es por eso que he recolectado los casos de uso hadoop más llamativos con los que podrías darte una idea.
Anteriormente vimos la introducción a Hadoop donde podías adquirir una visión general de cómo funciona, sus componentes y sus principales proyectos. Hoy quiero mostrarte que aunque cuando hablamos de Big Data nos referimos a grandes cantidades de datos, podremos sacar provecho de su tecnología y potenciarnos.
Es posible que hayas escuchado que uno de los usos más llamativos del Big Data actualmente viene de la mano del Marketing Digital, y es que estamos en el punto donde las organizaciones pueden analizar a sus consumidores (o leads) individualmente de manera que sea posible realizar promociones o campañas mucho más directas, menos costosas y menos intrusivas minimizando los famosos SPAM brindando una gran ventaja para todos nosotros.
Más aún con el auge de la Ciencia de los Datos donde no importa el tamaño o sector de la organización será necesario disponer de grandes volúmenes de datos listos para consumir y analizar.
Recuerda que no todas las organizaciones necesitan de Big Data, pero independientemente de su tamaño y sector, si necesitarán trabajar con grandes cantidades de datos.
Casos de uso prácticos de Hadoop
1. Construir una visión comprensiva del cliente
Hoy en día las organizaciones de todos los tamaños interactúan por distintos canales con sus clientes (redes sociales, newsletters , en sus tiendas, visitas personalizadas, etc), pero el comportamiento del cliente es casi totalmente impredecible sin Hadoop. Hadoop es capaz de almacenar y correlacionar los datos de las transacciones y el comportamiento de navegación en línea, lo que permite identificar las fases del ciclo de vida del cliente para aumentar las ventas, reducir los gastos de inventario y crear una base de clientes leal.
2. Acciones en tiempo real para la toma de decisiones
Cada vez son más las organizaciones se ven con la necesidad de identificar oportunidades en tiempo real, identificar picos que alerten riesgos en sus marcas o incluso los clientes insatisfechos por algún servicio o producto. Con esta premisa además podríamos realizar por ejemplo control de fraudes, control de disponibilidad, entender el comportamiento del cliente, premiarlo con incentivos, identificar problemas de seguridad mediante sensores, etc.
Hadoop posee un gran proyecto llamado Spark (Que también puede ser implementado sin necesidad de Hadoop) donde puedes implementar procesos de análisis en tiempo real vía streaming.
3. Optimizar sitios web o Clickstreams
Los datos de Clickstream son una parte importante del gran marketing de datos: le dice a las organizaciones qué clientes hacen clic y compran (o no compran). Sin embargo, el almacenamiento para ver y analizar estos conocimientos en otras bases de datos es costoso, o simplemente no tienen la capacidad para todos los datos de escape. Apache Hadoop es capaz de almacenar todos los registros y datos de la web durante años y, a bajo costo, permite entender las rutas de los usuarios, hacer análisis de carritos, ejecutar pruebas A / B y priorizar las actualizaciones del sitio.
4. Hadoop como complemento al Datawareouse / Datamarts
Un uso más estratégico, aquí vemos lo que llamo potenciación o evolución de nuestro DW. Podremos adquirir una gran ventaja competitiva pues entre otra cosas podríamos reducir el coste al hacer off-loading de datos o transformaciones (casos ELT) del DWH a Hadoop, incorporar nuevas fuentes de datos las cuales nuestros DW no podrían gestionar como fuentes de datos no estructuradas o mutables (como el punto anterior, documentos, redes sociales, encuestas, etc) y uno de os pilares más importantes en el mundo empresarial hoy por hoy…el poder incorporar nuevas técnicas de análisis sobre los datos.
Es de resaltar una propuesta muy ambiciosa y llamativa para las organizaciones que deseen sobresalir, no solo poder incluir nuevos datos y KPIs externos si no aprovecharlos y cruzar mucha más información.
5. Localizar y personalizar promociones
Hadoop es una plataforma de cambio de juego que puede combinar tanto el almacenamiento histórico y el flujo de datos en tiempo real para permitir a las organizaciones localizar y personalizar sus promociones. Por ejemplo con aplicaciones para móviles podríamos enviar a los usuarios de aplicaciones notificaciones push personalizadas basadas en la ubicación geográfica para que los clientes cercanos a una tienda sean notificados de una promoción o producto específico que les atraiga. El acceso al historial de búsquedas en línea y la ubicación geográfica también son útiles para promover anuncios en las fuentes de las páginas de medios sociales de los clientes.
6. Data Archiving
Debido a que Hadoop es una tecnología de bajo coste para el almacenamiento y acceso a los datos. Podremos valernos de conseguir almacenar grandes bancos de datos históricos, que por su composición cuentan con accesos poco frecuentes y SLAs relajadas, Hadoop te permite construir una infraestructura para cubrir las necesidades. Podrás contar con almacenamiento de muchos años los cuales te permitirá disponer de ellos para análisis futuros, calcular predicciones o simplemente como un gran banco documental.
7. Repositorio centralizado de datos
Veámoslo como un DW distribuido un nivel mucho más estratégico donde prima la necesidad de centralizar los datos por ejemplo de todas sus sucursales, tiendas, ventas, etc. minimizando los silos independientes, permitiendo un cross-selling sinérgico, análisis multi-canal, unificación de KPIs y mucho más. Éste caso se apoya en la capacidad, tanto en almacenamiento como en procesamiento, de utilizar cualquier tipo de dato existente en la organización (o fuera de ella), y con escalabilidad ilimitada. Hadoop permite, además, abrir los datos a distintos enfoques o tecnologías de procesamiento: predictivos, regresivos, batch, online, MapReduce, SQL, R, SAS, etc. (siempre sobre los mismos datos y sobre la misma plataforma).
8. Análisis de sensores y operativa digitalizada
Este uso es particularmente emergente dentro de las organizaciones donde producen pedidos o productos a escala, podrías imaginarte conocer el estado actual de todo el flujo de la producción o disponer y almacenar mediante sensores la temperatura de algún componente dentro de la preparación de un producto (como su temperatura o estado) de manera que puedas prever riesgos, reduzcas los costos y mejores la eficiencia operativa.
9. Análisis de sentimiento
Cuando hablamos de análisis de sentimiento automáticamente pensamos en redes sociales, es cierto que la manera más directa de identificar que piensan de nosotros, nuestra marca u organización es leer los comentarios, cantidad de me gusta, cuanto nos comparten, etc. Pero también debemos tener presente que todos estos datos son no estructurados y que nos llegan en masa (grandes cantidades). Por eso gracias a la versatilidad de Hadoop puedes implementar este tipo de soluciones para tu organización.
10. (IoT) Internet de la cosas
Internet de la cosas nos provee un mundo de nuevas posibilidades, con la creciente creación de APIs y nuevos desarrollos podemos obtener datos de casi cualquier dispositivo (Bicicletas, Neveras, Casas, etc). Pero para almacenar, tratar y disponer de dichos datos necesitamos disponer de una plataforma escalable y potente como lo es Hadoop, permitiendo almacenar distintos tipos de datos y a grandes flujos de velocidad.
Como acabas de leer Hadoop abre un mundo de posibilidades, donde no solo se benefician las grandes organizaciones si no que gracias a su bajo costo de implementación y otras empresas que se encarguen de proveer estos servicios a bajo costo como SaaS, las empresa más pequeñas también pueden sacar provecho y hacer diferencia en sus respectivos nichos mejorando su competitividad.
Conocías alguno de los anteriores casos de uso de Hadoop? Te parece una gran ventaja implementar Hadoop como complemento estratégico? Podrías imaginarte otro caso de aplicación de Hadoop?
Hoy en día existen nuevas fuentes emergentes las cuales vienen de la mano con nuevos retos tecnológicos los cuales no logramos cumplir con los sistemas tradicionales, con el auge de la inminente necesidad de procesar grandes cantidades de datos existen soluciones que nos ayudan a solucionar dichas brechas en algunos aspectos. En este caso vamos a dedicar el artículo a una de las mayores soluciones tecnológicas que existen actualmente (y desde hace ya varios años atrás) la cual conocemos como Hadoop.
Como podríamos imaginarnos los primeros en encontrarse con problemas de procesamiento, almacenamiento y alta disponibilidad de grandes bancos de información fueron los buscadores y las redes sociales. Con la implementación de sus algoritmos de búsquedas y con la indexación de los datos en poco tiempo se dieron cuenta de que debían hacer algo y ya.
Fue así como nació el sistema de archivos de Google (GFS), un sistema de archivos distribuido capaz de ser montado en clústeres de cientos o incluso de miles de máquinas compuestas por hardware de bajo coste. Entre algunas de sus premisas contaba con que es más óptimo el tratamiento de pocos ficheros de gran tamaño que el tratamiento de muchos pequeños y que la mayor parte de las modificaciones sobre los ficheros suelen consistir n añadir datos nuevos al final en vez de reemplazar los existentes.
De la mano del GFS crearon Map-Reduce del cual hablaremos más adelante pero podríamos decir que es un modelo de programación cuya finalidad es paralelizar o distribuir el procesamiento sobre los datos a través de los clústeres.
Cabe mencionar que Google una vez creo semejante solución público la documentación donde describe aspectos de arquitectura y funcionamiento tanto del GFS como del Map-Reduce el cual sirvió como base para la creación de Hadoop.
Aquí están los links de la documentación publicada por Google:
Así pues de la mano del gran avance de Google fue como nació Hadoop con Doug Cutting un trabajador de Yahoo!. Gracias a que había sido el creador de distintos proyectos en Open Source con anterioridad distribuyó de la misma manera a Hadoop.
De igual manera se hace mención a Facebook ya que es parte de la popularización y contribución al desarrollo de Hadoop, pues bien fue una de los primeros en implementar uno de los clústeres más grandes y se atribuye el desarrollo de <Hive> el cual permite realizar consultas similares al SQL sobre los datos en un ambiente distribuido.
Que es Hadoop?
Es un framework Open Source de Apache que nos permite implementar plataformas Big Data altamente distribuidas, funcionales y escalables sin depender de la inversión de licencias y ni de hardware. Gracias a que está escrito en el lenguaje de programación Java disponemos de diversas aplicaciones o proyectos adicionales que le potencian además de su propia adaptación del modelo de programación Map-Reduce para el procesamiento de grandes bancos de datos incluyendo estructurados y no estructurados.
Hadoop está diseñado para crear aplicaciones que procesen grandes volúmenes de datos de manera distribuida a través de Map-Reduce. Además gracias a que trabaja con almacenamiento y procesamiento local (pero distribuido) nos permite trabajar tanto con Clústeres de un solo nodo como por miles de nodos ofreciendo un alto nivel de tolerancia a errores.
Componentes de Hadoop
Consta principalmente de dos componentes los cuales se dividen en almacenamiento/distribución de los datos y el procesamiento de los mismos:
Hadoop Distribuited File System HDFS
Es un sistema de archivos distribuidos el cual permite difundir los datos a través de cientos o miles de nodos para su procesamiento. Aquí es donde se proporciona redundancia (Los datos están repetidos o replicados en varios nodos) y tolerancia a fallos (Si falla algún nodo se reemplaza automáticamente).
En su funcionamiento el sistema de archivos HDFS divide los datos en bloques donde a su vez cada bloques se replica en distintos nodos de manera que la caída de un nodo no implique la pérdida de los datos que éste contiene. De esta manera se facilita el uso de modelos de programación como Map-Reduce, ya que se puede acceder a varios bloques de un mismo fichero en forma paralela.
Map-Reduce
Es el corazón de Hadoop el cual permite el fácil desarrollo de aplicaciones y algoritmos bajo el lenguaje Java para el procesamiento distribuido de grandes cantidades de datos.
Dentro del ecosistema las aplicaciones desarrolladas para el framewrok Map-Reduce se conocen como Jobs, éstos se componen de las siguientes funciones:
Map (Mapeo): Encargada de la división de las unidades de procesamiento a ejecutar en cada nodo y de su distribución para su ejecución en paralelo. Aquí a cada llamada se le asignará una lista de pares key/value.
Shuffle and sort (Combinación y Orden): Aquí se mezclan los resultados de la etapa anterior con todas las parejas clave/valor para combinarlos en una lista y a su vez se ordenan por clave.
Reduce: Aquí se reciben todas las claves y listas de valores haciendo si es necesaria la agregación de las mismas.
Antes de continuar es necesario mencionar que Hadoop fue diseñado para ejecutar procesamiento distribuido por lo cual tendremos nodos maestros (Para cubrir las funciones de control del almacenamiento y procesamiento) y nodos esclavos (donde se almacenan o tratan los datos).
Una de las grandes ventajas de Hadoop es que inicialmente no necesitamos disponer de grandes requerimientos de hardware para montar nuestra propia aplicación, gracias a que su escalabilidad nos permite crecer conforme lo requieran las exigencias de nuestro proyecto.
Es importante recalcar que no es lo mismo realizar el conteo de 1000 palabras a contar todas las palabras de todos libros de una biblioteca nacional, debemos ser realistas, así que si te encuentras con una solución real de Big Data donde debes procesar Petabytes de datos si será necesario contar con exigentes requerimientos.
Los tipos de instalación son:
Stand Alone (un solo nodo)
La instalación Stand Alone nos permite configurar un despliegue de Hadoop donde todos los servicios tanto de maestro como de esclavo se ejecutan en un solo nodo al mismo tiempo que solo trabaja con un thread.
Una de las grandes ventajas es que nos puede servir para probar aplicaciones sin tener que preocuparnos de concurrencias de ejecución, además es una buena manera de entrar en el mundo de Hadoop pues experimentaras aspectos a tener en cuenta de instalación y configuración los cuales seguramente necesitaras en un futuro.
Pseudo-distribuida
Esta instalación al igual que la anterior también se monta sobre un solo nodo, todos sus servicios corren sobre éste pero la diferencia es que permite ejecutar múltiples threads.
Gracias a que ejecutamos aplicaciones multi-threads podemos experimentar la ejecución de aplicaciones sin necesidad de disponer de múltiples computadoras pues aquí empezamos a aprovechar mucho mejor los distintos núcleos de nuestro procesador.
Totalmente Distribuida
Tal como su nombre lo indica es aquí donde instalamos y configuramos un ambiente completamente distribuido donde dispondremos de un maestro y varios esclavos aprovechando completamente la paralización.
Este es el tipo de instalación para un ambiente de producción donde consideraremos grandes racks y nodos bien dotados de procesador y memoria para divisar los verdaderos beneficios de Hadoop.
Personalmente considero muy importante experimentar por los tipos de instalación desde la más básica hasta la avanzada pues nos permitirá obtener experiencia y conocer aspectos técnicos como configuración de variables de entorno, archivos de configuración del servidor maestro y esclavo, como compilar nuestras aplicaciones Map-Reduce y su funcionamiento, etc.
Ecosistema Hadoop
Gracias a la creciente comunidad Open Source existen distintos proyectos y herramientas que ofrecen funcionalidades adicionales las cuales son consideradas parte de un gran ecosistema pensado en apoyar las distintas etapas de un proyecto Big Data.
A continuación realizo una clasificación personal de las mismas a modo de orden y guía para entenderlas mucho más fácil.
Cada una se acompaña del link oficial y si está disponible un link donde puedes aprender más detalle sobre la misma.
Es un proyecto construido para capturar y analizar grandes volúmenes de datos principalmente logs. Debido a que está construido sobre Hadoop hereda escalabilidad y robustez con el uso de HDFS y Map-Reduce al mismo tiempo que provee adicionalmente un grupo de herramientas flexibles y potentes para visualizar, controlar y analizar los datos.
Es una herramienta distribuida para la recolección, agregación y transmisión de grandes volúmenes de datos de diferentes orígenes altamente configurable. Ofrece una arquitectura basada en la transmisión de datos por streaming altamente flexible y configurable pero a la vez simple de manera que se adapta a distintas situaciones tales como monitorización logs (control de calidad y mejora de la producción), obtención de datos desde las redes sociales (Sentiment Analysis y medición de reputación) o mensajes de correo electrónico.
Es una de las herramientas que deberías tener en cuenta si deseas potenciar tu sistema BI pues su funcionalidad permite mover grandes cantidades de datos entre Hadoop y bases de datos relacionales al mismo tiempo que ofrece integración con otros sistemas basados en Hadoop tales como Hive, HBase y Oozie <links>.
Utilizando el framework Map-Reduce transfiere los datos del DW en paralelo hacia los distintos Clústeres de manera que una vez ahí puede realizar análisis más potentes que el análisis tradicional.
Otra aplicación interesante con la que podremos analizar grandes volúmenes de datos no estructurados tales como texto, video, datos de audio, imágenes, etc… y obtener conocimiento que sea relevante para el usuario final. Por ejemplo a partir de un fichero plano, poder descubrir que entidades son personas, lugares, organizaciones, etc…
Este proyecto es uno de mis favoritos, es una librería escrita en Java diseñada como un motor de búsqueda de textos. Es adecuada para casi cualquier aplicación que requiera la búsqueda de texto completo. Lucene permite indexar cualquier texto o palabra (el texto puede contener letras, enteros, reales, fechas y combinaciones) permitiéndonos después encontrarlos basados en criterios de búsquedas como palabra clave, términos, frases, comodines y muchas más.
Es una herramienta data warehousing que facilita la creación, consulta y administración de grandes volúmenes de datos almacenados en Hadoop. Cuenta con su propio lenguaje derivado del SQL, conocido como Hive QL, el cual permite realizar las consultar sobre los datos utilizando Map-Reduce para poder paralelizar las tareas. Por esta misma razón, se dice que Hive lleva las bases de datos relacionales a Hadoop.
Otra gran ventaja es nuestro camino a la evolución del BI es que posee drivers de conexión tales como JDBC/ODBC por lo que facilitaría notablemente la integración con nuestros sistemas proporcionándonos extensión en análisis y procesamiento sin cargar el proceso diario.
Es la base de datos de Hadoop distribuida y escalable. Su principal uso se encuentra cuando se requieren escrituras/lecturas en tiempo real y acceso aleatorio para grandes conjuntos de datos. Debido a que su base es hadoop adquiere las sus capacidades y funciona sobre HDFS. Puedes almacenar en un amiente distribuido tablas sumamente grandes incluso hablando de billones de registros por millones de columnas, la manera de soportar esta cantidad de datos es debido a que es una base NoSQL de tipo Columnar por lo cual no es posible realizar consultas SQL.
Este proyecto nos permite desarrollar algoritmos escalables de Machine Learning y Data Mining sobre Hadoop. Soporta algoritmos como recomendación, clustering, clasificación y filtro colaborativo, también si es el caso podremos crear algoritmos para encontrar patrones, que aprendan sobre los datos y que los clasifique una vez termine su fase de aprendizaje.
Este proyecto nos permite analizar grandes volúmenes de datos mediante el uso de su propio leguaje de alto nivel llamado PigLatin. Sus inicios fueron en Yahoo donde sus desarrolladores pensaban que el Map-Reduce era de muy bajo nivel y muy rígido por lo cual podías tardar mucho tiempo en la elaboración y manutención.
Así pues nace Pig con su propio lenguaje y trabaja sobre Hadoop traduciendo las consultas del usuario a Map-Reduce sin que éste siquiera lo note. De esta manera provee un entorno fácil de programación convirtiendo las paralelizaciones en dataflows, un concepto mucho más sencillo para el usuario del negocio.
Pig tiene dos componentes: su lenguaje PigLatin y su entorno de ejecución.
Pig provee un enfoque más analítico que a la construcción.
Debido a su fácil y potente uso es usado en procesos de ETL y en la manipulación y análisis de datos crudos.
Proyecto el cual nos permite planificar workflows para soluciones que realizan procesos o tareas Hadoop. Al igual que Pig, está orientado al usuario no experto por lo cual le permite definir fácilmente flujos de trabajo complejos sobre los datos.
Oozie funciona como un motor de workflows a modo de servicio que permite lanzar, parar, suspender, retomar y volver a ejecutar una serie de trabajos Hadoop (tales como Java Map-Reduce, Streaming Map-Reduce, Pig, Hive, Sqooq…) basándose en ciertos criterios, como temporales o de disponibilidad de datos. Los flujos de trabajo Oozie son grafos no cíclicos directos -también conocidos como DAGs- donde cada nodo es un trabajo o acción con control de dependencia, es decir, que una acción no puede ejecutarse a menos que la anterior haya terminado.
Es un lenguaje de consulta funcional y declarativa que permite la manipulación y procesamiento de datos en formato JSON e incluso semi-estructurados. Fue creado y liberado por IBM bajo Apache License 2.0. Además de ser pensado para trabajar con formato JSON también permite realizar consultas sobre XML, CSV, Archivos Planos y RDBMS.
Ya que es compatible con Hadoop puede ejecutar consultas de datos sobre HDFS generando automáticamente Jobs Map-Reduce solo cuando sea necesario y soportando procesamiento en paralelo sobre el Clúster.
Es un proyecto de Apache el cual brinda una infraestructura centralizada y servicios que permiten la sincronización del clúster. Zooquiper en pocas palabras se encarga de administrar y gestionar la coordinación entre los distintos procesos de los sistemas distribuidos.
Avro, es un sistema de serialización de datos creado por Doug Cutting, el padre de Hadoop.
Debido a que podemos encontrar distintos formatos de datos dentro de Hadoop, Avro se ocupa de que dichos formatos puedan ser procesados por distintos legajes de programación por ejemplo Java, C, C++, Python, Ruby y C#. El formato que utiliza para serializar el JSON gracias a su portabilidad y fácil lectura.
Hue es una herramienta enfocada en los administradores de las distribuciones Hadoop proporcionando una interfaz web para poder trabajar y administrar las distintas herramientas instaladas. Desde aquí puedes cargar o visualizar datos, programar y ejecutar consultas Pig o SQL, realizar búsquedas e incluso programar en pocos pasos un flujo de datos.
Una funcionalidad que independientemente de las herramientas que tengas instaladas en tu proyecto Big Data con Hadoop no puede faltar.
Espero te haya gustado el artículo hasta aquí esta introducción a Hadoop, en futuros artículos profundizaré sobre aquellos proyectos y herramientas capaces de permitirnos evolucionar nuestras soluciones BI.
Ya habías escuchado de Hadoop o de su ecosistema? Que proyectos o herramientas considerarías ideales para potenciar tus proyectos BI? Conoces algún otro proyecto?