
Una de las principales fuentes del Big Data son la bases de datos relaciones, en una organización pueden existir millones de registros en distintas tablas, transacciones por segundo o incluso muchos años de historia. Lo más probable es que no se exploten dichos datos y no se beneficien del gran potencial que tienen en su poder, pues procesar tal cantidad de datos con sistemas tradicionales es un gran reto.
Este es uno de los principales usos del Big Data, donde las organizaciones pueden contar con mucha historia almacenada esperando ser analizada en Hadoop (Map Reduce, Machine Learning, Predictive, etc). Es por eso que Hadoop cuenta con una herramienta llamada Sqoop la cual te permite transferir datos desde distintos RDBMS a Hadoop y de Haddop a RDBMS.
¿Qué es Sqoop?
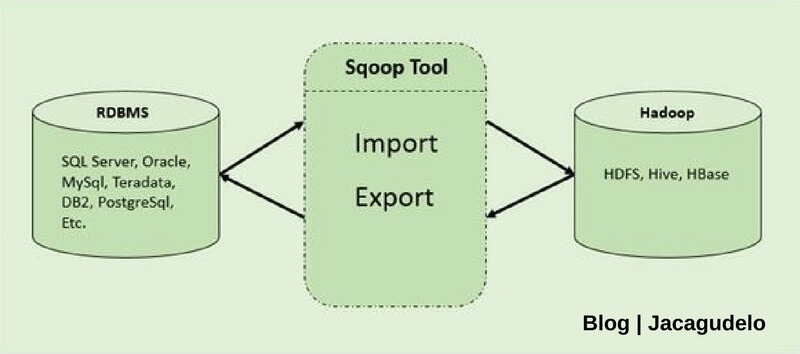
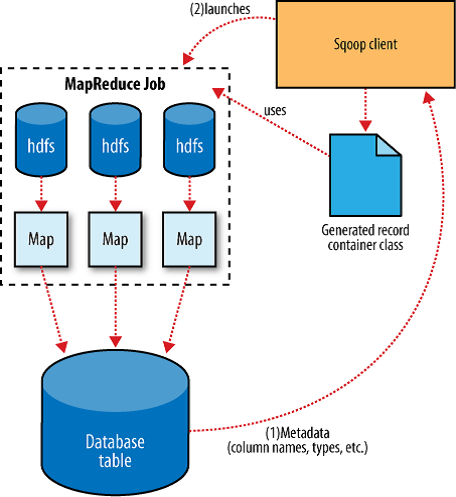
Sqoop es una herramienta cuya principal funcionalidad es transferir datos entre bases de datos relacionales o Data Warehouse y Hadoop. Sqoop automatiza la mayor parte de los procesos de transferencia, basándose en la base de datos para describir el esquema de los datos a importar, además para su funcionamiento utiliza MapReduce para importar y exportar los datos, lo que proporciona una operación en paralelo, así como tolerancia a fallos.
Sqoop le permite a los usuarios especificar la ubicación de destino dentro de Hadoop (pueden tablas Hive o HBASE) e instruir a Sqoop para mover datos de Oracle, Sql Server, Teradata u otras bases de datos relacionales al destino.
¿Cómo Trabaja Sqoop?
Sqoop funciona como una capa intermedia entre las bases de datos relacionales y Hadoop:
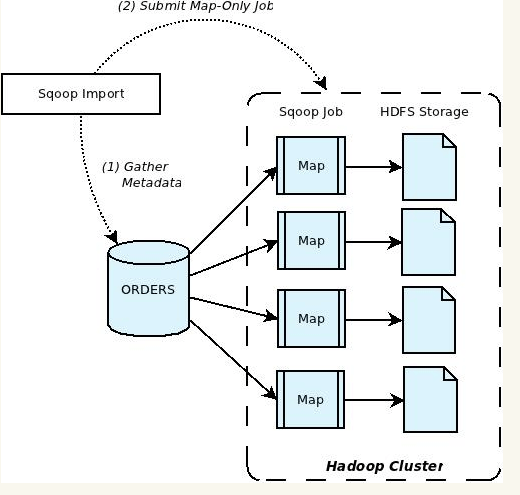
Import Sqoop
Sqoop escribe desde las tablas o consultas Sql específicas registro por registro paralelamente, por lo cual el resultado pueden ser múltiples archivos almacenados en HDFS con una copia de los datos importados. Estos archivos podrían ser txt separados por comas o tabulaciones, binarios Avro o SequenceFiles
Argumentos Comando Import
Al ver la siguiente lista de argumentos para realizar la importación, podemos ver que el proceso inicial no es del otro mundo y utiliza casi la misma estructura que si estuviéramos realizando una conexión a una base de datos específica desde cualquier lenguaje de programación, adicionándole por supuesto los datos de Hadoop:

Por ejemplo:
Importando desde Mysql
$ sqoop import –connect jdbc:mysql://database.example.com/employees –username jacagudelo –password 678456
Importando desde SQl Server
$ sqoop import –driver com.microsoft.jdbc.sqlserver.SQLServerDriver –connect <connect-string> …
Seleccionando datos a importar
Generalmente Sqoop selecciona todos los campos de la tabla o vista origen a importar manteniendo el orden natural de los mismos.
$ sqoop import –query ‘SELECT a.*, b.* FROM a JOIN b on (a.id == b.id) WHERE $CONDITIONS’ –split-by a.id /
–target-dir /user/foo/joinresults
Donde guarda los datos importados?
Por defecto Sqoop almacena los archivos de la importación en el directorio /foo dentro del directorio principal del sistema HDFS. Por ejemplo si el usuario utilizado es jacagudelo, Sqoop dejará los archivos de los resultados en la ruta /usr/jacagudelo/foo/(files).
Para ajustar este valor podemos hacer lo siguientes:
$ sqoop import –connnect <connect-str> –table emp –target-dir /dest
Export Sqoop
La herramienta de exportación exporta un conjunto de archivos de HDFS a un RDBMS. Los archivos dados como entrada a Sqoop contienen registros, que se llaman como filas en la tabla. Éstos se leen y analizan en un conjunto de registros y se delimitan con el delimitador especificado por el usuario.
Argumentos Comando Export

Los principales parametros utilizar son – – export-dir el cual especifica el directorio en HDFS que contiene los datos de los archivos y – – table o – – call que identifican respectivamente la tabla destina o procedimiento almacenado a ejecutar.
Algo a tener en cuenta al momento de exportar es que Sqoop toma por defecto todas las columnas, pero podremos especificar columnas puntuales con el comando – – columns delimitándolas por comas. La advertencia aquí es que las colummnas que no se eincluyan en el proceso serán enviadas con valor NULL por defecto por lo que si la tabla destino no tiene configurado dicho permiso terminará generando error el proceso Sqoop.
Por ejemplo:
$ sqoop export –connect jdbc:mysql://db.example.com/foo –table retail –export-dir /results/bar_data
Sqoop por defecto realiza un append en la tabla de destino, en esencia realiza un insert sobre cada registro. Al igual que con los campos en el caso anterior, las tablas destino podrían tener Primary Key con los cual podrían generar error de duplicidad. Este modo está destinado principalmente a exportar registros a una nueva tabla vacía destinada a recibir estos resultados.
En caso de que el destino sea una tabla existente, debemos adicionar el parámetro – – update – key donde Sqoop realizará la modificación del conjunto de datos existente en la base de datos destino. Cada registro de entrada se tratará como una instrucción UPDATE que modifica una fila existente. La modificación de la fila se determina por el nombre de columna especificado como llave –update-key.
Si ejecutamos el comando:
$ sqoop export –table bar –update-key id –connect jdbc:mysql://db.example.com/foo –export-dir /results/bar_data
Internamente el Job de Sqoop realizará lo siguiente:
UPDATE foo SET msg=’this is a test’, bar=42 WHERE id=0;
UPDATE foo SET msg=’some more data’, bar=100 WHERE id=1;
Tipos de Destino en Hadoop
Una de las principales virtudes de Hadoop es que nos brinda una gran variedad de proyectos disponibles para usar de acuerdo a nuestras necesidades, para este caso puntual contamos con 3 proyectos específicos:
- Hive: Como vimos en el artículo Hive nos proporciona un ambiente de Data Warehouse sobre Hadoop con su propio lenguae de consulta muy similar al SQL, lo cual nos vendría conveniente al querer explorar nuestros datos.
- HBase: HBase es una base de datos no relacional que nos permite realizar búsquedas rápidas de baja latencia en Hadoop. Agregar capacidades transaccionales a Hadoop, permitiendo a los usuarios realizar actualizaciones, inserciones y eliminaciones.
- Accumulo: Aunque muy poco conocida pero no menos importante, tenemos esta base de datos NoSql de tipo Key-Column la cual podemos utilizar a nuestras necesidades.
Conclusión sobre Sqoop
Como acabamos de ver, Sqoop es una poderosa herramienta para poblar desde nuestras bases de datos relacionales y evolucionar nuestros proyectos analíticos, con sus comandos podemos trasladar nuestros datos, analizarlos mediante cualquier otra herramienta como Pig o Hive sobre Hadoop y volver a retornar el resultado a nuestras bases. Una funcionalidad muy práctica y eficaz para nuestros proyectos.
¿Qué te pareció Sqoop? ¿Consideras que debe ser tenido en cuenta en una solución Big Data con Hadoop?



