Uno de las principales ventajas del Big Data son las tecnologías emergentes, las mismas nos dan la posibilidad de interactuar con distintas soluciones que satisfacen requerimientos puntuales en nuestro desarrollo (esto se conoce como persistencia poliglota).Gracias a la evolución del tratamiento de los datos tenemos muchas alternativas para su almacenamiento y análisis, las bases de datos NoSQL han tenido una gran aceptación en el mercado y poco a poco las organizaciones están empezando a perder el miedo a soluciones Open Source y han ido incluyendo esta tecnología a sus procesos de almacenamiento.
Una de estas nuevas tecnologías son las bases de datos NoSQL Documentales, estas bases son muy versátiles y la ventaja de no depender de un modelo fijo de datos da cierta dinámica en desarrollo y administración. Una de las bases de datos más importantes de la actualidad es MongoDB, la cual ha crecido abismalmente a lo largo de los años y cuenta con un sistema muy robusto de servicios y soporte.
Por otro lado encontramos el análisis de los datos, aquí nuevamente encontramos otra solución Open Source…hablo del Software R, ya muy conocido en nuestro medio.
Así que me gustaría tuvieras presente tanto si te enfocas en administrar los datos o en analizarlos, es que puedes combinar ambas soluciones para tu beneficio, tomando la versatilidad de los datos almacenados con el poder de analizarlos sin tener que distraerte en aprender algún otro lenguaje.
Desde R podemos realizar consultas directamente en nuestra base MongoDB mediante el paquete Mongolite.
El pasado 19 de Agosto de 2017 junto a Víctor Hugo Males (Data Science y también blogger) realizamos un meetup en la universidad Javeriana de Cali donde presentamos el uso de MongoDB desde R, mostrando la facilidad de manipular los datos almacenados en la base de datos documental y cómo el procesamiento a gran escala de los datos queda del lado del motor de la base librando nuestra memoria local. También hablamos un poco de Open Data y su uso.
A continuación te comparto el video de la charla realizada en la Pontificia Universidad Javeriana de Cali Colombia.
También te comparto las demás presentaciones del día:
Una vez decides emprender el camino del conocimiento de las Bases de Datos Big Data es necesario tener presente que conceptualmente son diferentes a las bases de datos relacionales. Entre ellas las bases de tipo documental como MongoDB que por su composición es una muy buena opción con la cual puedes empezar en este mundo, aunque veremos cambios conceptuales tendremos una visión clara de cómo nos podemos beneficiar de su uso.
Bases de Datos Documentales
Como hemos visto anteriormente, estas bases permiten almacenar estructuras de datos las cuales llamamos documentos que pueden ser de distintos tipos como XML, YAML y JSON principalmente, la gran ventaja es que los documentos no necesariamente deben seguir una misma estructura de manera que fácilmente podremos crear aplicaciones dinámicas y escalables.
Existen distintas bases de datos NoSQL documentales tales como: CouchDB, OrientDB, RavenDB, Terrastore, entre otras, hoy vamos a ver una base que goza de uan buena posición en el RankingDB y desde que empezó a tenido un considerable crecimiento incluyendo una comunidad cada vez más grande, hablaremos de MongoDB.
¿Qué es MongoDB?
Es una base de datos NoSQL cuya principal característica es almacenar la información en estructura documental más exactamente lo que conocemos como JSON (Java Script Object Notation), aunque internamente son almacenados en formato BSON (Que vendría siendo la representación binaria de cada documento).
La ventaja al almacenar los datos en formato documental es que gozamos de una ventaja muy interesante frente a las bases tradicionales y es precisamente disponer de un esquema dinámico, cómo así?… pues que no es necesario que todos los documentos almacenados tengan la misma estructura o el mismo esquema, veamos un ejemplo:
Ejemplo de documentos en base de datos NoSQL
En la anterior imagen podemos observar dos documentos con información de dos facturas y su respectivo detalle, como vemos ambos tienen internamente un array de documentos llamado “ítem”, el cual uno tiene dos objetos y el otro solo uno…de igual manera el primero tiene un array adicional de cadenas llamado “intereses” el cual no tiene el segundo.
Esta característica es muy interesante debido a que aparte de administrar y gestionar el espacio de almacenamiento en una sola operación podríamos obtener una gran cantidad de información.
Nomenclatura RDBMS vs MongoDB
Veamos la nomenclatura de los distintos términos de los componentes de ambos tipos de bases:
Nomenclatura MongDB vs RDBMS
Como podemos observar en la tabla anterior, ambos tipos de bases de datos manejan casi los mismos componentes..
Un aspecto muy importante a tener en cuenta es que los documentos no pueden exceder los 16 MB de tamaño, pero al mismo tiempo existe otra funcionalidad llamada GridFS cuya finalidad es extender dicha limitante para permitir almacenar documentos de GB o incluso TB (Podrías usar ésta opción en caso de que desees leer porciones de archivos de gran tamaño sin necesidad de tener que cargar todo su contenido en memoria).
Familiarizarnos con los términos no es tan complicado pues la lógica sigue la misma estructura que conocemos, por el contrario una de las principales diferencias y gracias a que MongoDB no soporta Joins debido a su estructura de datos desnormalizada, son los distintos metodos a tener presente en el modelado de datos los cuales veremos en el siguiente apartado.
Modelando datos en MongoDB
Como comenté anteriormente, debemos cambiar un poco nuestra lógica de modelado de datos…venimos de definir nuestros modelos de datos teniendo en mente siempre los requerimientos de la información solicitada y por supuesto las Formas de Normalización donde lo normal es llegar hasta la 3FN o incluso 4 y 5FN (Aunque existen muchos aspectos más pero viniendo al tema tratado resalto estas por el momento).
Debemos centrarnos en identificar el camino más corto para recuperar la mayor cantidad de información posible
Hasta aquí todos estamos familiarizados, por el contrario en MongoDB diseñamos nuestros modelos analizando y teniendo en mente el cómo vamos a recuperar la información, a que me refiero?…como observaste en la primer imagen (Ejemplo de documentos en base de datos NoSQL) podemos ver fácilmente que podemos almacenar distintos tipos de información en un solo documento, si lo llevamos a un modelo relacional fácilmente tendríamos las siguientes tablas: Factura, Detalle Factura , Cliente, Tipo de Pago, Intereses, Ítem y Tiempo.
Así mismo se debe tener presente como diseñar y elegir la estructura de los documentos, viendo la misma imagen podemos leer el contenido de dos maneras, puede ser tanto una colección de Clientes como de Facturas…pero el verdadero valor de ventaja estará representado en cómo necesitas obtener los datos.
Supongamos que es una colección de Clientes, si consultamos constantemente solo información del cliente pero muy de vez en cuando sus facturas, estaríamos desperdiciando memoria y procesamiento de la base pues debemos realizar un trabajo extra para extraer una cantidad de información innecesaria. Por el contrario si lo que necesitamos es consultar constantemente las Facturas realizadas, la información del Cliente y el detalle de lo facturado, sería una ventaja tener todo en un mismo documento pues con una sola consulta estamos obteniendo toda la información deseada.
Por supuesto cabe anotar que debes tener presente el crecimiento de los datos a futuro, por eso es importante saber que se quiere como finalidad del proyecto para así poder realizar un buen modelado de datos.
Veamos los distintos tipos de modelado de datos que podemos encontrar.
· Modelado Uno a Uno
En este modelado la finalidad es embeber datos altamente relacionados dentro de una misma estructura o documento, facilmente podemos incrustar o embeber documentos dentro de otros documentos. Al tener este tipo de modelo de datos desnormalizados nos permite recuperar y manipular los datos rapidamente.
Modelado Uno a Uno MongoDB
· Modelado Uno a Muchos
En este modelado la finalidad es identificar aquellos datos mucho más descriptivos relacionados entre sí y almacenarlos en una misma estructura, regularmente se identifican con arrays de distintos tipos como: documentos, cadenas, números y podrían representar por ejemplos datos como listas de direcciones, de libros, varias etiquetas, números telefónicos, amigos, colores favoritos, etc.
Modelado Uno a Muchos MongoDB
· Modelado Uno a Muchos con Referencias
Debido que no se soportan Joins por mantener un esquema desnormalizado, posee una funcionalidad que permite almacenar información relacionada en documentos separados dentro de una misma base de datos como en distintas bases de datos, lo que conocemos como un link en Oracle.
De igual manera existen dos opciones:
-Referencia Manuales
Usada principalmente para relacionar documentos entre dos colecciones.
Esta opción nos permite referenciar documentos de múltiples colecciones, la ventaja es que en éste caso también podemos indicar tanto la colección como la Database donde se encuentran.
Como vimos en el artículo de introducción al Big Data es necesario que se cumplan ciertas características:
· Alta Disponibilidad
Gracias a su funcionalidad Replica Set, podemos almacenar nuestra información en más de un servidor a la vez de manera que nunca se pierda disponibilidad si alguno llega a fallar y al mismo tiempo brinda durabilidad.
· Escalabilidad Horizontal
Sharding permite particionar nuestros datos a través de un Cluster de servidores permitiendo dividir nuestras cargas de disponibilidad, escalando fácilmente y de manera inmediata.
· Atomicidad
Una gran ventaja al no disponer de transacciones, es que las operaciones se realizan de manera atómica, lo que quiere decir que si insertamos un dato una vez el servidor confirme la operación éste permanecerá hasta que se modifique o elimine…funcionando de igual manera para todas las operaciones, con esto garantizamos consistencia en los datos.
· Almacenamiento de grandes bancos de información
La combinación de las funcionalidades anteriores hacen de ésta base de datos NoSQL una buena opción siempre que aplique y dé solución a nuestros requerimientos, un buen diseño nos brindara una solución altamente escalable y disponible.
· Schemaless
Como vimos en el apartado anterior, nos permite definir la estructura de los datos que vamos a almacenar según sea el requerimiento, esto no quiere decir que no debamos controlar tanto el desarrollo de nuestra aplicación como el de nuestra base….por el contrario es necesario definir bien nuestros modelos de datos pues a futuro puede impactar enormemente en el rendimiento y el crecimiento de la misma.
Recursos
Si esta introducción a MongoDB te ha gustado, de seguro estarás interesado en profundizar los distintos temas tratados y en aprender mucho más. Gracias a su gran acogida y al crecimiento exponencial de uso de la misma, han creado una serie de recursos gratuitos de los cuales puedes sacar bastante provecho, yo por mi parte he tomado todo lo que voy a referenciarte y aunque la mayoría es en ingles también hay material en español así que te invito a que profundices!
· Mongo University
Es un espacio donde los mismos desarrolladores y profesionales la base de datos comparten su conocimiento al público, existen cursos de distintos niveles y perfiles. Lo increíble es que puedes tomar los cursos que desees y además te obsequian un certificado que puedes colocar en tu perfil de Linkedin, puedes ver en mi perfil en la sección de Certificaciones como lucen.
· Mongo Webinars
Tiene la misma finalidad que el anterior pero la diferencia es que es en vivo y en formato webinar, donde además de interactuar con un experto también lo haces con profesionales interesados en el tema, existen secciones en español pero debes estar pendiente…puedes registrarte al instante.
· Mongo MUG
Haz escuchado de la aplicación Meetup? Pues esta aplicación funciona como una red social que permite a sus usuarios realizar reuniones en la vida real. Actualmente existen más de 100 grupos alrededor del mundo, puedes elegir el más cercano y prepararte para la próxima reunión!
· Mongo Community
Por supuesto también puedes encontrar absolutamente todo lo relacionado con MongoDB en la siguiente dirección
· Mongo Blog
Posiblemente uno de los recursos principales, además de contar con información sobre los avances de las versiones y sus mejoras también encontrarás artículos prácticos donde aprenderás muchísimo.
Espero que te haya gustado el artículo, te motive a leer y aprender un poco más de esta increíble base de datos NoSQL. Te informo que en los siguientes artículos profundizare sobre el almacenamiento, manipulación de documentos, explicaré como configurar ReplicaSet, Sharding…nos veremos pronto! ¿Qué opinas de MongoDB ? Te parece interesante y te gustaría probarla? Tienes alguna idea en la que creas que puedes utilizarla?
En anteriores artículos hemos visto distintos aspectos que debemos tener presente antes de iniciar nuevos proyectos con fuentes emergentes, por eso es necesario conocer algunas características que deben cumplir las Tecnologías Big Data a usar, de manera que nos permitan obtener el máximo valor de las fuentes con las que antes no contábamos y que al día de hoy nos pueden brindan el conocimiento agregado frente a nuestra competencia.
Que debemos considerar?
Debemos tener la capacidad de almacenar, procesar y visualizar datos de manera amigable y eficaz que nos permita en poco tiempo tomar determinaciones como: lanzar nuevas campañas no solo de captación si no también de fidelización o retención de clientes, de identificación de tendencias que permitan el diseño y creación de nuevos productos o servicios, incluso poder determinar bajo ciertas lecturas de distintos aparatos electrónicos el estado de salud actual y a futuro de los pacientes.
Todo lo anterior es posible siempre y cuando identifiquemos y conozcamos las características del gran abanico de tecnologías especiales que podemos utilizar para nuestro proyecto Big data, las cuales al igual que en ocasiones anteriores, debemos tener presente que dependemos del alcance y de los requerimientos de nuestro proyecto, alinear los objetivos que queremos cumplir y elegir las que mejor se adapten para nuestra solución.
Veamos cuales serían:
Distribución de grandes cantidades de información.
Almacenamiento y tratamiento de datos no estructurados o datos emergentes.
Tratamiento de los datos con análisis avanzados en tiempo real o histórico.
Visualización adecuada y adaptada a los nuevos datos.
Distribución de grandes cantidades de información.
Permitir distribuir cargas y minimizar tiempos de procesamiento y acceso a la información es algo muy importante a tener en cuenta, disminuir los costos y obtener una solución robusta que garantice el almacenamiento y procesamiento de grandes flujos de información nos permitirá escalar cada día nuestras tomas de decisiones.
Dentro de este ámbito podremos encontrar tecnologías como:
Hadoop
Stream analytics
Data integration
Tecnología de Distribución de datos – Ecosistema Hadoop
Almacenamiento y tratamiento de datos no estructurados o datos emergentes.
Otro gran reto es poder almacenar los distintos tipos de datos, datos que claramente no podremos almacenar con buen rendimiento y administración en sistemas transaccionales, en este aspecto encontramos las bien conocidas bases de datos NoSql, de manera que combinadas con los puntos anteriores o simplemente con su uso independiente, nos permiten crear soluciones altamente escalables.
Dentro de este ámbito podremos encontrar bases de tipo:
Documentales
Columnares
Clave-Valor
Grafos
Tencologías de Almacenamiento – NoSql
Tratamiento de los datos con análisis avanzados.
Una vez obtenida y almacenada la información es necesario pasar a un aspecto importante del proyecto, como explotar y extraer conocimiento del mismo, para conseguir tal fin es necesario capacitarnos o dotarnos de profesionales con un perfil más analítico y estadista, conocidos como Científicos de Datos, quienes nos ayudan a descubrir aspectos que no conocemos de los datos, obtener conocimiento predictivo y accionable a partir de los datos y comunicar historias relevantes de nuestros negocios a partir de los datos…en pocas palabras, nos dotan de lo que no sabemos y lo que nos gustaría saber.
Dentro de este ámbito podremos encontrar muchas tecnologías entre algunas:
R, Weka, SPSS, SAP HANNA, SAS
Map Reduce, Text Mining
Procesamiento en paralelo, Clustering, KNN, Machine learnin, Redes bayesianas, etc.
Análisis en la nube
Tecnología de Analítica de Datos
Visualización adecuada y adaptada a los nuevos datos.
Un aspecto muy importante es poder disponer de una herramienta que te permita visualizar la información una vez tratada, que sea intuitiva, rápida y en la puedas dar sentido a los datos, como bien buscamos obtener, relacionar, analizar y extraer el gran valor de los datos, facilitar la toma de decisiones, segmentar y clasificar mejor a nuestros clientes nos brinda de un valor agregado frente a nuestra competencia.
Dentro de este ámbito podremos encontrar algunas tecnologías como:
Tecnología de Visualización de Datos – Mapas Carto
Como vimos en el artículo, hay distintos aspectos a tener presente a la hora de elegir las distintas Tecnologías Big Data para nuestros proyectos, la aproximación anterior nos dá una idea de lo necesario que es planificar y detallar todo lo necesario antes de intentar hacer realidad un proyecto de Big Data.
Que piensas de las anteriores Tecnologías Big Data? Consideras adicionar alguna…cual sería? Conocer alguna Tecnología Big Data que complemente las anteriores mencionadas?
Muchos de nosotros estamos interesados por el Big Data, pero es necesario conocer un poco más a fondo aspectos teóricos para poder elegir la base de datos NoSql que mejor se adapta a nuestro proyecto, eso lo proporciona en gran medida el Teorema CAP.
Como lo vimos en el anterior post, existen muchas bases de datos NoSQl, que a su vez nos proveen distintas ventajas necesarias para implementar soluciones altamente distribuidas y escalables, las cuales dentro de sus características principales se encuentra el cumplimiento del Teorema CAP, el cual representa dentro del diseño de nuestra implementación un reto para definir que es lo más importante, si la Consistenciao la Disponibilidad.
Teorema CAP
El Teorema CAP aplica en ambientes altamente distribuidos, el primero en referenciarlo fue el profesor Eric A. Brewer, quien en el año 2000 en un simposio del ACM sobre los principios de la computación distribuida (PODC)…explicó que cuando se trata de diseño y despliegue de aplicaciones en entornos distribuidos solo podremos garantizar 2 de los siguientes 3 requerimientos:
The three requirements are: Consistency, Availability and Partition Tolerance, giving Brewer’s Theorem its other name – CAP.
2 años más tarde, fue comprobado y convertido en teorema, por lo cual, veamos a fondo cada uno de los requerimientos anteriormente mencionados:
Consistency (Consistencia)
Todos los nodos deben garantizar la misma información al mismo tiempo, si insertamos datos (todos los nodos deben insertar los mismos datos), si actualizamos datos (todos los nodos deben aplicar la misma actualización a todos los datos) y si consultamos datos (todos los nodos deben devolver los mismos datos).
Para tal efecto la comunicación entre los nodos debe ser de suma importancia, podríamos por ejemplo, emitir confirmación de inserción de un dato, una vez dicho dato se grabo en todos los nodos de nuestra réplica.
Availability (Disponibilidad)
Independientemente si uno de los nodos se ha caído o a dejado de emitir respuestas, el sistema debe seguir en funcionamiento y aceptar peticiones tanto de escritura como de lectura.
Una vez se pierde comunicación con un nodo, el sistema automáticamente debe tener la capacidad de seguir operando mientras éste se restablece y una vez lo hace, se debe sincronizar con los demás.
Partition Tolerance (Tolerancia al Particionado de Red)
El sistema debe estar disponible así existan problemas de comunicación entre los nodos, cortes de red que dificulten su comunicación o cualquier otro aspecto que genere su particionamiento.
Por lo general los ambientes distribuidos están divididos geográficamente, donde es normal que existan cortes de comunicación entre algunos nodos, por lo cual, el sistema debe permitir seguir funcionado aunque existan fallas que dividan el sistema.
A partir de lo anterior y dependiendo de lo definido en el proyecto, solo podemos garantizar 2 de los 3 aspectos mencionados anteriores. Siendo la disponibilidad desde mi punto de vista uno de los principales aspectos a tener en cuenta…pues debemos ser conscientes que en estos momentos son cada vez más impacientes nuestros clientes y menos susceptibles a esperar el restablecimiento del servicio (Aunque muchas veces se resuelvan los problemas en cuestión de segundos).
Veamos ahora los posibles escenarios o combinaciones permitidas para cumplir lo anterior.
Cuál escenario elegir?
Para tal efecto veamos un ejemplo: Supongamos que nuestra organización se dedica a la distribución de productos de aseo, somos una organización líder en el mercado y constantemente recibimos pedidos de todo tipo de sectores y todo tipo de cliente en nuestro país. Demandamos tantos pedidos que decidimos dividir y sectorizar nuestro país en 4 grandes Clúster principales y cada uno cuenta con 4 nodos en réplica, quienes se encargaran de tomar los pedidos y dar respuestas internas y externas.
Uno de nuestros clientes desea realizar un pedido por una cuantiosa suma de dinero, aportando un gran ingreso en el Sector A, pero uno de los nodos de la réplica del Sector A ha perdido comunicación con los demás…
Ahora veamos cómo aplicar nuestro ejemplo a cada posible escenario entregado por el Teorema:
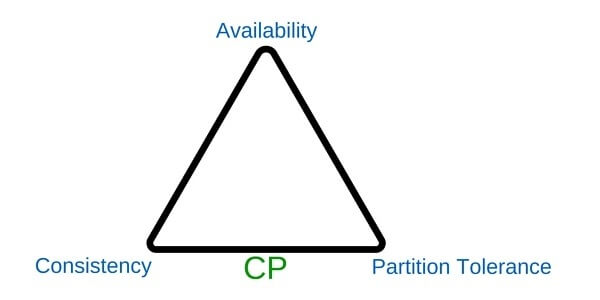
1. CP (Consistency – Partition Tolerance)
El sistema siempre garantizará Consistencia aunque existan problemas de conexión entre los nodos (Particiones de red) y no se asegura Disponibilidad.
Teorema CAP – Consistency, Partition Tolerance
Como toleramos particiones de red, nuestro sistema recibe la petición, pero como además priorizamos consistencia, es necesario que el pedido se aplique y confirme en todos los nodos, como uno de ellos no está disponible…el pedido no se puede realizar.
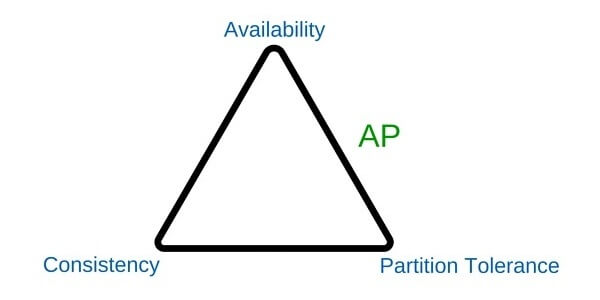
2. AP (Availability – Partition Tolerance)
El sistema siempre estará Disponible aunque existan problemas de conexión entre los nodos (Particiones de red). Aunque pueda mostrar datos temporalmente Inconsistentes.
Teorema CAP – Availability, Partition Tolerance
Siguiendo con el ejemplo, aquí toleramos particiones de red igualmente por lo cual el sistema recibe y aplica la petición, como no garantizamos consistencia, no es necesario que se confirme el pedido en todos los nodos.
3. CA (Consistency – Availability)
El sistema siempre estará Disponible con información Consistente. Por lo cual el sistema no soporta perdida de comunicación entre los nodos (Particiones de red).
Teorema CAP – Consistency, Availability
En este caso como no soportamos particionamiento, el sistema debería fallar y presentar un mensaje a nuestro cliente de “Inténtalo más tarde por favor”, puesto que prácticamente no estaríamos garantizando ningún tipo de consistencia.
Si por el contrario no existiera particionamiento, aplicaríamos todas las peticiones y garantizábamos consistencia confirmando cada petición en todas las réplicas, debido a que estamos en un ambiente distribuido es poco probable que se dé el escenario ideal donde nunca se creen particiones de red.
Igualmente vemos con lo anterior que es necesario priorizar en la disponibilidad, personalmente no utilizaría el escenario CA pues prácticamente quedaríamos fuera de servicio total, lo que causaría miles de llamadas para reportar errores, quejas o incluso perdidas de clientes.
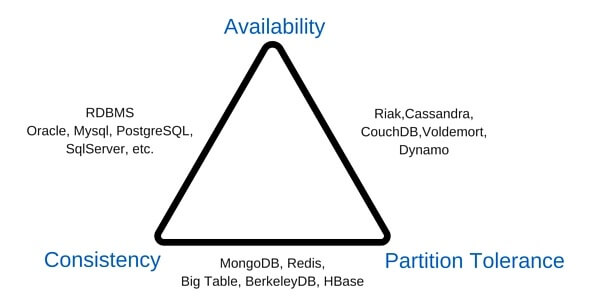
Como acabamos de ver, es sumamente importante definir desde el principio como desea disponer de la información el cliente, en algunos casos podríamos combinar distintas bases NoSQL que nos permita cubrir ciertas necesidades presentadas anteriormente, todo es un juego de análisis y dimensionalidad de nuestro proyecto, para tal efecto y mayor guía, veamos una clasificación de las distintas Bases de datos, donde claramente veras como una buena elección y combinación de bases te puede ser de gran ayuda.
Que te pareció el Teorema CAP? Que piensas respecto a la teoría y a la práctica del teorema? Alguna experimentaste la necesidad de elegir alguna opción del Teorema CAP?
Hoy en día nos enfrentamos a un gran cambio de paradigma en cuanto a almacenamiento y procesamiento de datos se trata, gracias a la evolución de grandes compañías como Google, Amazon, Linkedin, Facebook y muchas más, han salido a luz una seria de soluciones en modalidad Opens Source que nos benefician en gran medida.
Las Bases de Datos NoSQL tienen como principal característica que solucionan los principales problemas que presentábamos en la actualidad:
Escalamiento horizontal: Ya no necesitamos depender de un proveedor de hardware para potenciar nuestras soluciones. Disponibilidad de los datos: Podemos distribuir en cuanto equipo y capacidad económico dispongamos si necesidad de que sean robustos. Solución a fallas o cortes de red: Disponemos de un ecosistema interconectado el cual siempre en gran medida vamos a tener disponibilidad de los datos.
Actualmente contamos con una tecnología que mezcla una seria de características que nos ayudan en cierta parte a cubrir los aspectos anteriormente expresados, tal como lo dije, éste cambio de paradigma nos permite entre otras cosas almacenar y tratar grandes bancos de información, tener información disponible, información incluso definida geográficamente y tolerar errores por falta de conexión…éstas soluciones las conocemos como Bases de DatosNoSQL.
Un poco de historia…
El término NoSQL en cierta forma se referenció hace un buen tiempo. Inicialmente fue usado a finales de los 90’s cuando Carlo Strozzi desarrolló su propio SGBD el cual no usaba SQL, ésta base de datos almacenaba sus tablas dentro de archivos ASCCI donde cada tupla de valor era representada por un fila de campos separados por Tabs, debido a que no usaba SQL para consultar los datos, básicamente ejecutaba Scripts sobre el Shell de UNIX.
Luego con el inminente éxito Google en el 2003 se dio a luz el primer proyecto de bases de datos NoSQL llamado BigTable y un poco después apareció Marklogic para el 2005, por supuesto todo esto debido a la necesidad de cubrir ciertas limitaciones que encontraban en sus sistemas SGDB tradicionales, las cuales debido al crecimiento de usuarios, de datos y procesamiento cada vez mayor y de peticiones en tiempo real, debían buscar otras alternativas de almacenamiento y disponiblidad de datos.
A partir de éste momento distintas organizaciones consolidadas como Linkedin, Facebook, Last.fm, Powerset, Couch.io hicieron lo mismo y presentaron sus proyectos en un distintivo meetup de San Francisco en Junio del 2009 presentado por Johan Oskarsson donde explicaban y debatían ciertos aspectos sobre estas nuevas bases de datos.
Entrando en materia
Ya teniendo claro de donde provienen estas fascinantes bases de datos, vamos a verlas un poco más a fondo.
Las bases de datos NoSQL tienen como principal característica la no utilizan del lenguaje de consulta SQL, conocido por todos nosotros, pues al proveer un ambiente altamente distribuido sería muy complicado realizar algún tipo de Join o consulta entre todos los servidores de un Cluster. También están diseñadas para permitir almacenar y gestionar grandes bancos de información…por ejemplo, Facebook hasta hace un año atras almacenaba, consultaba y analizaba más de 30 Petabytes de datos generados por los usuarios!!!
Existen distintos tipos de bases de datos y cada una nos permite solucionar distintos problemas debido a su enfoque particular.
Al existir distintos tipos de bases NoSQL, podremos obtener la capacidad de utilizar distintas tecnologías dentro de un mismo ambiente, cada una colaborando en un aspecto y funcionalidad puntual, esto se conoce como Persistencia Poliglota.
Características
Dentro de las principales características podemos encontrar:
No usan SQL como lenguaje de consulta estándar
La información almacenada no requiere un formato o esquema definido (Schemalees)
Permiten escalabilidad horizontal
No garantizan ACID, esto para mejorar el rendimiento y disponibilidad
Aunque a partir de los últimos años se han venido creando distintos tipos de bases datos, presentaré las más utilizadas. Es necesario aclarar y recordar que es importante analizar si verdaderamente es necesario aplicar cualquiera de estas bases para solución de nuestros problemas, pues debemos dedicar tiempo a investigación o incluso dinero si deseas tercerizar el desarrollo.
1. Documentales
Como su nombre lo indica, en ellas podemos almacenar datos de tipo documento, los cuales pueden ser de tipo XML, JSON o BSON principalmente. Como indiqué anteriormente, no es necesario seguir una estructura definida para cada documento, lo cual brinda inmensa versatilidad. Son muy comunes y se acoplan muy bien a soluciones donde deseamos extender.
A continuación veamos la comparación de dos documentos:
Ejemplo de base de datos NoSQL Documental
Algunas de las bases de datos más populares de éste tipo son:
MongoDB, CouchDB, OrientDB, RavenDB
2. Familia de Columnas o Columnares
Almacenan los datos cambiando nuestra lógica transaccional de filas a columnas. Tienen como característica principal que dentro de una fila podemos encontrar distintas columnas relacionadas a un Key y a su vez cada columna contiene un par (Key-Value) que hace referencia al campo y su valor. La ventaja que presenta es que no es necesario que todas las filas tengan las mismas columnas ni la misma cantidad de columnas, permitiendo adicionar columnas a cualquier fila y en cualquier momento.
Veamos una imagen como referencia:
Ejemplo de bases de datos NoSQL Column Family
Algunas de las bases de datos más populares de éste tipo son:
Este tipo de bases podríamos decir que son las más simples, en ellas podemos almacenar por cada registro una tupla de Key-Value. Para obtener los valores simplemente consultamos por el Key y por supuesto es necesario definir una Key que defina nuestra estructura lo mejor posible, entre tanto podemos encontrar tipo de valores como: Listas, String, Arrays, Arrays ordenados, Hash con los cuales podríamos relacionar otros campos, Arrays de bits. Variando de producto en producto.
Veamos una representación:
Ejemplo de bases de datos NoSQL Key-Value
Algunas de las bases de datos más populares de éste tipo son:
Redis, Riak, Voldemort (LinkedIn), Amazon DynamoDB, Berkeley DB
4. Grafos
Estas bases de datos particularmente nos ayudan a almacenar datos relacionados bajo muchos niveles, imaginémonos representaciones de amigos de mis amigos o productos que relaciones a distintos clientes de distintas nacionalidades. Al ser de tipo grafo, tenemos dos elementos distintivos: Los Nodos, cuya finalidad es representar las entidades (Personas, Productos) con sus respectivas propiedades (Cuit,Nombre) y las Relaciones o Aristas, cuya finalidad será representar tanto el tipo como la dirección de nuestra relación (Gustos, Si amigo o no, Ubicación) con sus respectivas propiedades. También podemos hacer consultas transversales de modo que podemos ampliando el rango de resultados.
Veamos una representación:
Ejemplo bases de datos NoSQL Grafos en . Fuente: cmaps
Algunas de las bases de datos más populares de éste tipo son:
Neo4J (eBay), Inifinite Graph, FlockDB
Algunas veces podemos encontrar que alguna base de datos entra en más de una clasificación, esto debido a que sus características le permiten adaptarse a distintas aplicaciones y soluciones.
Como podemos ver, tenemos un gran abanico de soluciones capaces de brindarnos distintas capacidades para potenciar nuestras plataformas BI Tradicionales o para empezar nuestros proyectos de Big Data. Debemos analizar sus funcionales y nuestro problema a raíz de poder cubrir nuestras necesidades.
Habías escuchado alguna de las bases de datos NoSQL mostradas anteriormente? Cuál de éstos tipos te parece más interesante? Cómo podrías usarlas? Haz usado alguna de las anteriores?