Gracias al auge del Científico de Datos, escuchamos con frecuencia uno de los software más influyentes en la actualidad analítica y estadística llamado R. R nos permite entre muchísimas cosas trabajar con DataFrames de datos (realizar carga, tratamiento, análisis e interpretaciones) a fin de descubrir por ejemplo patrones, tendencias, índices o predicciones entre muchas más.
Actualmente si usas o consideras usar R debes tener presente que el análisis de los datos está limitado por la memoria que dispongas localmente y solo usa un core, así que trabajar con grandes cantidades de datos no es muy práctico.
Durante un tiempo me estuve preguntando: Podría distribuir los análisis (códigos) hechos en R sobre un cluster de datos para permitir el análisis de grandes cantidades de datos?
En cierta forma podría responder de distintas maneras.
Por ejemplo: “convierte tu código a Map Reduce y ejecútalo sobre Hadoop”, “carga tus datos, trátalos y analízalos con Pig”…pero estaríamos duplicando nuestro código ya hecho en R.
Así que me pareció muy interesante escribir un artículo donde se pueda responder ésta pregunta, y la respuesta es Si!, si podemos distribuir nuestros análisis (código) hechos en R, imagínate usar los más de 10.000 paquetes que tiene R en un ambiente escalable y distribuido!
La solución para convertir R a un ambiente escalable viene de la mano de la unión de R con uno de los proyectos más poderosos para el procesamiento de grandes cantidades de datos…Spark, el cual gracias a la comunidad de desarrolladores crearon un paquete llamado SparkR.
Que es SparkR?
SparkR es un paquete el cual está basado en un Data Frame distribuido el cual permite procesar datos estructurados o tratados (dplyr) con sintaxis familiar para los usuarios de R.
Por su parte Spark proporciona un motor de procesamiento distribuido, múltiples origines de datos y estructuras de datos en memoria. R, por el contrario, proporciona un entorno dinámico, interactivo, más de 10.000 paquetes de análisis a elegir y visualización.
SparkR combina las ventajas de Spark y R en un solo paquete
Que es un SparkDataFrame?
Un SparkDataframe es una colección de datos organizados dentro de columnas. Conceptualmente esto es equivalente a una tabla en un RDBMS o un dataFrame en R, pero mucho más optimizados. Una de las ventajas es que puede construirse desde una amplia gama de fuentes tales como: archivos de datos estructurados, tablas en Hive, bases de datos externas, tramas de datos locales de paquetes de R existentes o incluso formatos emergentes populares como Avro.
Cómo funciona?
Para trabajar con SparkR debemos utilizar una sesión o sparkSession la cual permite conectar nuestro programa R con el cluster Spark. Para crear una sesión usamos simplemente la instrucción sparkR.session pasándole algunas opciones como por ejemplo: el nombre de la aplicación o cualquier paquete que dependa directamente de spark, ect.
El método para crear los SparkDataFramesR desde distintos origines de datos es mediante el read.df.
Veamos un poco de acción creando un SparkDataFrames desde distinta fuentes:
# Creando un SparkDataFrame local
df <- as.DataFrame(faithful)
# Creando desde data source Avro
sparkR.session(sparkPackages = "com.databricks:spark-avro_2.11:3.0.0")
# Creando desde un JSON único
people <- read.df("./examples/src/main/resources/people.json", "json")
# Creando desde múltiples JSON
people <- read.json(c("./examples/src/main/resources/people.json",
"./examples/src/main/resources/people2.json"))
# Creando desde csv
df <- read.df(csvPath, "csv", header = "true", inferSchema = "true", na.strings = "NA")
# Creando desde Hive
sparkR.session()
sql("CREATE TABLE IF NOT EXISTS src (key INT, value STRING)")
sql("LOAD DATA LOCAL INPATH 'examples/src/main/resources/kv1.txt' INTO TABLE src")
# Queries expresadas en HiveQL
results <- sql("FROM src SELECT key, value")
# Cómo obtener resultados de un SparkDataFrame
head(results)Para más detalle sobre read.df encuentras la documentación oficial.
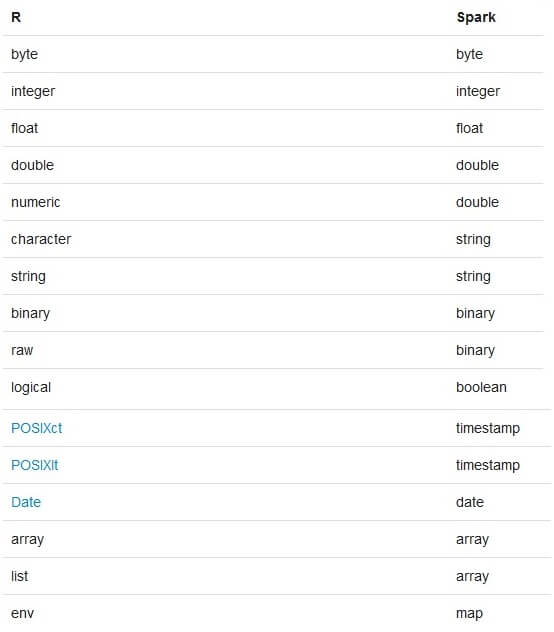
Mapeo de Tipos de datos entre R y spark
Cómo veremos a continuación existe una similitud entre los tipos de datos más similares y solo existe una pequeña variación:
Arquitectura SparkR
La arquitectura de SparkR está compuesta por 2 componentes principales: Un Driver conformado por JVM y R el cual permite enviar programas R a un cluster Spark y por otro lado los distintos Worker’s los cuales permitirán ejecutar los programas R sobre Spark.

Esto hace posible que las operaciones ejecutadas sobre el paquete SparkR automáticamente sean distribuidas a través de todos los nodos que hacen parte del cluster.
Una de las grandes ventajas de utilizar el JVM para invocar funciones de Spark desde R es satisfacer un enfoque flexible donde el administrador del cluster Yarn pueda soportar distintas plataformas como Windows, Linux, etc.
Ventajas que encontramos
- Operaciones con sparkDataFrames como selección de registros y columnas, agrupación, agregación, entre otras.
- Operaciones que pueden ser aplicadas directamente sobre columnas tales como el uso de funciones aritméticas.
- Aplicación de funciones definidas por los usuarios conocidas como UDF.
- Ejecuciones de funciones distribuidas usando spark.lapply.
- Ejecución de consultas SQL desde sparkR.
En resumen, SparkR proporciona una interfaz R sobre Apache Spark permitiéndoles a los usuarios realizar análisis a gran escala. Actualmente SparkR se encuentra en la versión 2.1.0. Por supuesto todas sus funcionalidades son de código abierto y puedes descargarlo desde aquí http://spark.apache.org, aquí la documentación oficial http://spark.apache.org/docs/latest/sparkr.html
Conclusión sobre SparkR
Aunque muchos de seguro hemos usado R tal vez no teníamos presente este paquete, las capacidades de poder procesar datos distribuidos y en grandes cantidades nos crea un abanico de oportunidades únicas en nuestro campo, espero que te allá parecido interesante éste artículo!
¿Qué te pareció SparkR? ¿Ya habías escuchado hablar de R a gran escala? ¿Te gustaría probarlo…cómo lo planearías?