Es interesante el avance tan sorprender del campo del Internet de las Cosas en la actualidad, poder conectar cualquier dispositivo a internet es fascinante, pero dónde y cómo se almacenan los datos? Cómo se gestionan éstos datos? Y Cómo podríamos aprovechar esta gran oportunidad en Big Data?
IoT + Big Data
Hace algunos años ni siquiera imaginábamos la posibilidad, por ejemplo, de que nuestro cepillo dental nos avise sobre la existencia de caries y que automáticamente nos solicite cita con el dentista, que nuestros cubiertos nos digan la velocidad en la que comemos para mejorar nuestra forma de comer o que incluso que nuestro inodoro analice nuestra orina y en base a los resultados diarios y periódicos nos recomiende la dieta más adecuada…así como las anteriores existen innumerables casos de aplicación del Internet de las Cosas o IoT de las cuales podemos sacar suficiente provecho, desde los desarrolladores hasta quienes gestionamos datos y por supuesto las industrias que quieran estar a la vanguardia.
No es de extrañar que nos llegue un correo electrónico periódico con el estado actual de nuestro coche o motocicleta antes de salir de casa con datos como el nivel de aceite, la iluminación, estado del motor, de los frenos y demás, todo esto es posible gracias a la posibilidad de obtener distintos tipo de información, en distintos formatos y en grandes cantidades cada momento, eso es algo que no vemos a simple vista porque solo nos llega el resultado pero desde el punto de vista técnico existiría una gran relación entre IoT y el Big Data.
La idea de llegar al punto de conectar a internet cualquier dispositivo nos crea una gran oportunidad de crecimiento exponencial de datos, disponer con nuevos bancos de datos que acompañen las estadísticas convencionales conocidas de que hoy en día donde se generan por minuto 204 millones de emails, 1.8 millones de Likes y se suben alrededor de 200 mil fotos en Facebook y se envía 278 mil de Like en Twitter es algo por lo que necesariamente debemos estar preparados.
Nuevos Bancos de Datos
Cada vez es más evidente el crecimiento abismal de los datos y hoy en día gracias al abanico de posibilidades que nos brinda el IoT incluso se podría triplicar en los próximos años.
Imaginemos que tenemos algunos electrodoméstico de nuestra casa conectados a internet como por ejemplo: Lámparas, Ventiladores, Aires Acondicionados, Nevera, Lava ropa y Lava Vajilla, cada uno con un dispositivo recolector de datos que captura distintos tipos y cantidades de datos a la vez, útiles para brindarnos análisis en tiempo real donde tendremos alertas de qué nos hace falta en la nevera y solicitar pedido automático al supermercado, programar remotamente la ejecución del lavarropa o incluso encender nuestro aire acondicionado y ambientar nuestra casa poco tiempo antes de que lleguemos.
Pero algo que debemos tener presente es que para que los datos lleguen a nuestras manos en las aplicaciones, los datos tuvieron que sufrir un proceso de tratamiento y normalización para llegar a la veracidad para que sean funcionales para nosotros, es aquí donde entra en juego la oportunidad para el Big Data.

Oportunidad Big Data
Una organización desea abrir un nuevo punto de venta pero desea elegir su mejor opción entre 3 lugares distintos, para tal efecto propone conocer de primera mano el flujo de personas que transitan por cada lugar en cada instante y por cada día de la semana. Para este caso se decide ubicar varios sensores de proximidad en cada uno de los lugares, transmitiendo vía WIFI mediante un API hacia los puntos de recepción de los datos en la central de la organización.
Dependiendo del flujo de personas podríamos recibir grandes cantidades de información a distintas horas del día, toda esta información vendría en formato predefinido por cada sensor que bien podría ser xml, JSON, Semi estructurado o incluso un formato propio por cada fabricante.
Almacenar y tratar los datos generados aquí proporcionaría información valiosa donde se identificará la cantidad de personas por hora y día en cada sitio elegido de manera que permita guiar a la organización a tomar su mejor decisión que en este caso sería abrir su punto de venta donde mejor le convenga.
Retos como el anterior donde existirá una creciente y constante fuente de transmisión de datos, es de suma importancia contar con soluciones que permitan extraer información valiosa de ello, esto lo podemos conseguir actualmente apoyándonos con tecnologías como Hadoop que proporciona una gran cantidad de soluciones que se pueden adaptar a nuestras necesidades de procesamiento. Prácticamente podríamos tratar al IoT dentro del Big Data como una nueva fuente emergente de datos, la cual podríamos combinar fácilmente con set de datos Open Data que contengan información de Cajeros Automáticos en la zona para facilitar el retiro y pago pronto, vías de acceso más cercanas para identificar las horas pico o de tráfico lento para aprovechar y realizar publicidad en sitio o incluso las rutas de los distintos medios de transporte por cada lugar e identificar paradas cercanas.
Retos IoT + BigData
Todo esto nos lleva a plantearnos algunos retos a cubrir con el manejo de la gran cantidad de datos generados por la nueva oleada del IoT, que como hemos visto en artículos anteriores son aquellos que por su composición y estructura debe cumplir todo proyecto de Big Data:
Recopilación de los datos:
Permitir incluir como nueva fuente de datos y combinar con datos existentes de manera que permita generar valor de mayor peso a la toma de decisiones.
En este caso poder combinar en una sola visualización los datos de cada sensor con datos de los asesores ventas que tienen segmentos de personas cerca a los lugares y con datos Open Data que permita dar una visión presente y a futuro en materia de movilidad por cada lugar, etc.
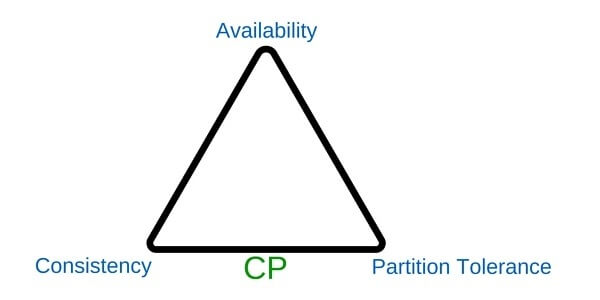
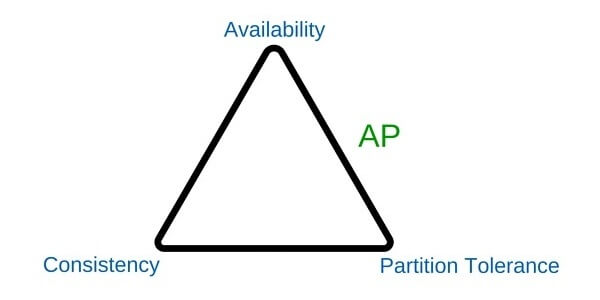
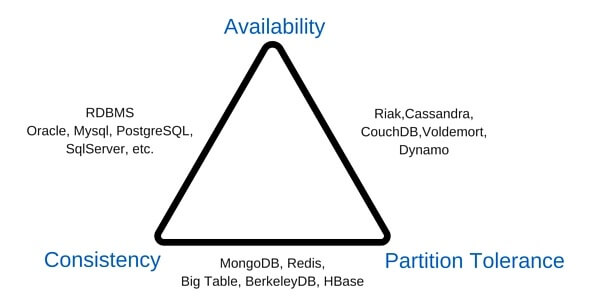
Almacenamiento de los datos:
Bien podríamos decidir hacer uso de las distintas bases NoSql, llevar nuestro proyecto a la nube o bien llegar al punto de almacenar los datos en bases relacionales.
Aquí recordamos el concepto poliglota, debemos ser capaces de poder almacenar toda esta combinación de datos y poder convertirlos en un solo repositorio de información.
Análisis y Visualización de los datos:
Permitir identificar visualizar la información al tiempo que permita crear patrones o tendencias sobre los datos recolectados, poder generar valor a partir de la gran masa de información generada adicional a la existente es uno de los principales retos.
Conclusión
Debemos prepararnos para la llegada de grandes bancos de información desde una nueva fuente llamada IoT, falta poco para que se haga masivo el uso de APIS y de datos Open Data en cualquier área de negocio y es ahí donde debemos estar preparados, capacitados y con el conocimiento necesario para sacar el máximo provecho a todos estos datos.